
Simulação de mercado (Parte 21): Iniciando o SQL (IV)

Introdução
Olá pessoal, e sejam bem-vindos a mais um artigo da série sobre como construir um sistema de replay/simulação.
No artigo anterior Simulação de mercado (Parte 20): Iniciando o SQL (III), expliquei um pouco sobre o comando SELECT. Mas para que realmente venhamos a utilizar o SQL de forma um pouco mais adequada. Ou melhor dizendo, que venhamos a fazer uso de algo que torna, usar o SQL, uma alternativa melhor, do que ter que programar uma aplicação que faria o mesmo trabalho. Ou seja, manter e nos permitir manipular bancos de dados. Precisamos ver um outro conceito. Este outro conceito é que faz toda a diferença quando o assunto é banco de dados. Estou falando sobre as chaves. Que podem ser primarias ou estrangeiras.
Mas apenas do MetaEditor nos permitir fazer as coisas usando o SQLite. Se você está começando e deseja aprender de forma mais consistente a trabalhar com SQL. Será preciso você fazer uso de uma ferramenta um pouco mais elaborada. Detalhe: Não estou falando que o MetaEditor não seja funcional. Mas para entender algumas coisas, o MetaEditor não se adéqua. Isto por que o propósito dele é outro. Ou seja, editar e compilar códigos escritos em MQL5. O fato de ele nos dá algum auxílio para usar o SQLite, não é o suficiente para o que precisamos de fato. Isto quando o assunto é aprendizado.
Então, para este caso específico, vou tomar a liberdade de sugerir uma outra ferramenta. Isto por que, ela é voltada a de fato trabalhar com o SQLite. Apesar de que usando o MySQL, ou qualquer outra plataforma para trabalhar com SQL. Iriamos de fato, ter o mesmo tipo de resultado. Isto pelo motivo, de que nos artigos anteriores, acredito ter deixado bastante claro, que não importa o sistema que você vier a usar para acessar o SQL. Todos conseguirão fazer a mesma coisa, desde é claro você utilize apenas e somente a sintaxe do SQL. Não fazendo uso de algo presente apenas naquela variação específica do SQL.
A ferramenta que proponho é o DB Browser. Ela é de código aberto, escrita em C++ e pode ser baixada gratuitamente no GITHub. No final deste artigo, deixarei a referência de onde você pode acessar o instalador da ferramenta. Uma das vantagens do DB Browser, é o fato de que ele facilitará em muito o entendimento de várias coisas. Já que existem traduções para outros idiomas. O que para muitos, que não tem domínio do inglês irá ajudar bastante este fato.
Um outro detalhe, é que diferente do MetaEditor, onde você não pode editar, salvar e utilizar um script de SQL. No DB Browser, você poderá fazer isto. Este tipo de coisa ajuda bastante no início do aprendizado. Mas quem já tem conhecimento em SQL, e o utiliza apenas para pesquisar um banco de dados. Usar uma ou outra ferramenta não fará diferença. Então fica a seu critério qual ferramenta utilizar.
Na imagem abaixo, mostro a interface do DB Browser. Claro que nesta imagem, eu removi algumas opções do mesmo, já que elas não se fazem necessárias para o que exploraremos.
Mas antes de começarmos a ver a questão sobre chaves primarias e chaves estrangeiras. Quero explicar uma coisa que talvez você venha a ter alguma dúvida. Ainda mais se procurar se aprofundar no assunto de SQL.
Por que da mudança de estratégia?
Talvez você venha a ficar um pouco incomodado e até mesmo frustrado, caso tente usar o SQL em qualquer implementação. Existem alguns administradores, que quando vão contratar um analista de banco de dados, muitas vezes exige que ele saiba trabalhar com uma determinada implementação. Por exemplo: Você pode estudar SQL Server e não conseguir uma vaga de trabalho por que, no local é usado o MySQL. Ou pode ver alguém dizendo que o Oracle é melhor do que outras implementações do SQL. Nos artigos anteriores, tentei mostrar que as pessoas que pensam assim. Na verdade, não sabem nada sobre bancos de dados. Elas apenas, imaginam que algo é melhor ou pior. Elas não tem a devida noção de como realmente a coisa funciona nos pormenores. E ficam ali querendo julgar algo que elas de fato não entendem.
Se você for utilizar um banco de dados, ou implementação que faz uso de um servidor. Terá uma forma de acessar o banco de dados. A forma mais comum de se fazer isto é através de soquetes. Antes de falar sobre o SQL, expliquei em alguns artigos como você faz para trabalhar com soquetes. Se bem, que ali, a ideia era além de explicar o funcionamento dos soquetes, também mostrar como fazer para que o Excel se comunicasse com o MetaTrader 5. Isto de uma forma bidirecional. Ou seja, tanto o Excel quanto o MetaTrader 5, poderiam enviar dados um para o outro. Você não ficaria limitado a usar um RTD ou DDE para transferir dados. Isto por que neste caso, apenas o Excel receberia os dados. Mas sabendo usar soquetes, podemos fazer bem mais.
Aquele mesmo conhecimento, que foi mostrado ali, pode ser usado para que o MQL5. Ou um executável rodando no MetaTrader 5, possa trabalhar com o SQL, a fim de acessar um banco de dados. Tudo que você precisará saber, é como trabalhar com os comandos do SQL, e também como enviar e receber informações via soquete. O resto é história. Já que bancos de dados baseado em servidores, são bem mais práticos quando o assunto é fluxo de informações. Para deixar mais claro, é o seguinte: Um banco de dados, hospedados em um servidor SQL será muito mais extensível que um banco de dados hospedado em um arquivo.
Porém, quando usamos o SQLite, a premissa é hospedar o banco de dados em um arquivo. Não que você fique limitado a isto. É sim possível usar um servidor SQLite. Mas normalmente usamos arquivos quando o SQLite é empregado. Isto nos trás algumas limitações e transtornos. Algumas destas limitações são aceitáveis, já que muitas das vezes banco de dados, será usada apenas por uma aplicação específica. Em outros casos estas limitações, nos forçará a mudar de estratégia nos forçando a usar um servidor de SQL.
Porém como o propósito aqui, é ser didático. Mas principalmente, lhe mostrar que não precisamos programar certas coisas. E devemos usar ferramentas já existentes quando isto for possível. Tais limitações que aparecem quando o banco de dados está contido em um arquivo, não serão de fato um problema. Mas tenha isto em mente: Um servidor de SQL será sempre superior em diversos pontos a uma implementação que utiliza um arquivo para manter o banco de dados.
Explicado este ponto. Deste momento em diante, deixaremos o MySQL um pouco de lado. Apesar de eu gostar bastante dele. Precisamos focar primeiro no que realmente é necessário. Talvez futuramente em um outro artigo, eu venha a explicar como você pode usar soquetes para programar um banco de dados. Mas por hora, vamos ver uma outra coisa, e para que o assunto não se misture com este, vamos a um novo tópico.
Por que de chaves primárias e chaves estrangeiras?
Para explicar isto, que é algo bastante complicado de entender, pelo menos para quem não entende banco de dados. É preciso primeiro explicar uma outra coisa. Que também é bastante complicada de ser entendida por quem não conhece nada de programação. Ou seja, um assunto está ligado a outro. Mas vamos ver se consigo explicar, a você caro leitor, que muito provavelmente não sabe, ou não tem os conceitos corretos sobre banco de dados. O por que de existir chaves primárias e estrangeiras. Porém se você não sabe nada sobre programação, aconselho a você estudar pelo menos o básico de alguma linguagem de programação. Isto para entender alguns dos conceitos que utilizarei nesta explicação.
O motivo de existir chaves primárias e estrangeiras, e note que estou sempre as colocando juntas. É o mesmo que separa, bancos de dados relacionais dos bancos de dados não relacionais. Xi, agora complicou. Já que muita gente pensa que só existe um único tipo de banco de dados. Ou seja, grande parte quando ouve falar em banco de dados, já logo pensa que existe um relacionamento entre chave e valor. Mas a coisa não é bem assim. O problema é o mal uso de alguns conceitos. O conceito chave - valor, não está de maneira alguma dizendo que um banco de dados é ou não do tipo relacional. Na verdade o conceito chave - valor se estende um pouco além do que rege algumas ideias. Para conseguir entender isto. Vamos esquecer por uns instantes, a questão de banco de dados. E vamos pensar como era as coisas, antes do termo banco de dados surgir.
A forma mais simples de aplicação do conceito chave - valor é usando um array. Se você sabe o que é um array, sabe que cada índex, ou posição do array pode conter um valor ou registro. Ok. Então usando um índex, que seria o equivalente a uma chave, você conseguirá obter o registro daquela posição, que seria o equivalente ao valor. Sabendo disto, você pode modificar, apagar ou fazer qualquer coisa com tais dados. Isto é o básico do básico da coisa toda.
Se você, colocar este mesmo array, que está em memória dentro de um arquivo. Poderá criar uma formatação a fim de conseguir recriar facilmente o array original. Isto quando for ler o arquivo de volta para a memória. E novamente isto é o básico da coisa toda. Neste ponto, você pode pensar o seguinte: Bem, eu como programador, posso criar toda uma série de rotinas e procedimentos a fim de modificar, pesquisar, organizar, apagar entre outras coisas, qualquer registro no array. Note que neste ponto, você mesmo sem perceber acabou de criar um banco de dados. Isto por que você está usando exatamente as mesmas coisas que um banco de dados faria.
Então para você acessar qualquer registro, ou valor dentro do que agora é um banco de dados, você carregaria o arquivo para o array em memória, faria os procedimentos necessários e logo depois salvaria o array de volta no arquivo. Este tipo de coisa, é algo que é muito praticado e explicado quando começamos a aprender programação. Porém, até onde sei, ninguém trata este tipo de coisa como sendo um banco de dados. O motivo disto? Bem , quem sabe. Mas a verdade é que você mesmo sem perceber, terá criado um banco de dados, pessoal e particular.
Porém este tipo de solução muitas das vezes não é escalável. Ou seja, você não consegue facilmente transferir informações entre aplicações diferentes. E é neste ponto que o conceito de banco de dados começa a fazer sentido. Já que você pode, usando algo que outros também usarão, no caso o SQL, escrever um banco de dados que pode ser usado por diversas aplicações. Por isto que desde o início, eu falei que mesmo podendo fazer as coisas, as vezes é melhor usar o que já existe.
No entanto, toda esta explicação, ainda não respondeu a questão que abre o tópico. Mas calma, meu caro leitor, ainda vamos chegar lá. Mas como, agora você já tem uma ideia, bem básica do que seria um banco de dados. Podemos passar para o próximo ponto. Ou seja, qual a diferença entre um banco de dados relacional e um não relacional e por que esta diferença existe? Bem, apesar de esta ser uma pergunta simples, a resposta não é tão simples. Algumas pessoas, por conta de mais ou menos experiência, vão logo dizer: Um banco de dados relacional usa o SQL, já um que não é relacional não usa o SQL. Mas eu até queria que a resposta fosse simples assim. Porém ela não é. A diferença entre um banco relacional e um não relacional está na forma como o conjunto chave - valor é colocado no banco de dados.
Virgem Maria, se antes já estava complicado, agora é que ferrou de vez. Mas como assim? Como a diferença pode está na forma como o conjunto chave - valor é colocado no banco? Isto não faz o menor sentido. De fato, no primeiro momento, isto não faz o menor sentido, mas conforme você for experimentando e trabalhando com banco de dados. Em algum momento, você irá perceber isto. Mas para que você possa pelo menos compreender o que estou dizendo, mesmo que isto venha a parecer loucura. Vou tentar explicar este ponto. Apesar de ser algo realmente complicado de explicar.
Uma das principais características de um banco de dados relacional é a sua integridade. Ou melhor dizendo, é a capacidade do banco se manter íntegro. Mesmo quando, tentamos fazer com que ele perca tal característica. Você pode pensar que todo banco de dados é integro. Mas existem casos em que esta integridade não é a prioridade. E quando isto acontece, temos algo que não é desejável, quando o banco de dados precisa ser integro. Temos a duplicação de conjuntos chave - valor. Mas espere um pouco ai. Esta duplicação não deveria de fato ocorrer, isto por que cada índex que seria uma chave, estaria ligado a um registro que seria um valor. De fato, você está certo, se pensou assim. Porém se você pensou isto, é por que ainda está pensando na questão do array. Agora a coisa ficou um pouco mais complicada. No caso do array, cada posição representa um valor. Então não tem como você ter uma posição que represente dois valores diferentes. Isto de fato está correto.
Mas e se no lugar do índex, ou posição, fosse utilizado uma outra coisa, como por exemplo, um valor ou uma string que representaria agora o índex, ou chave no caso. Agora a coisa começa a ter uma certa aparência bastante familiar. Para entender isto, vamos pensar em algo que tem sido bastante comum nos dias atuais. Programação em Python. E por que vou usar o Python na explicação? O motivo é que no Python, temos um conceito que se encaixa perfeitamente no que preciso, para explicar esta coisa de banco relacional e não relacional. Além de que o Python também pode usar arrays. Então a explicação ficará bem mais coesa.
No Python existe uma coisa chamada dicionário. Um dicionário, seria a grosso modo dizendo, um tipo de array, onde cada índex, teria um campo que seria a chave e um outro campo que seria o valor. Ou seja, não é mais o índex no array, que indicaria qual o valor na qual a chave estaria ligada. Você pode colocar a chave em qualquer índex, que ainda assim, ao pesquisar pela chave, você encontraria o valor correspondente. Esta analogia é perfeita. Já que agora podemos ter chaves iguais que representam valores diferentes, assim como também podemos ter valores igual sendo representados por chaves diferentes. Neste ponto, o banco de dados que seria criado pelo dicionário em Python, seria um banco de dados não relacional. Simples assim. Assim como isto foi feito em Python, você poderia usar o SQL para fazer a mesma coisa. Ou seja, você criaria uma coluna que conteria os valores que seriam utilizados como chaves.
Em uma outra coluna você colocaria uma correspondência de cada chave a um valor de registro. Sem as devidas medidas de proteção, o banco de dados, mesmo escrito em SQL se tornaria um banco de dados não relacional. Virão que apesar de parecer ser algo simples. Entender um pouco sobre diversas coisas diferentes pode nos ajudar a entender melhor alguns conceitos. Mas tudo que foi visto até neste ponto, é apenas para explicar como podemos ver um banco de dados. E como você poderia ficar tentado em programar uma série de rotinas e procedimentos, apenas para fazer o que o SQL pode fazer. Ou você acha, que não conseguiria criar um dicionário de Python usando para isto o SQL?
Neste ponto, surge um detalhe, que talvez seja interessante ser falado. Isto antes de explicar os bancos de dados relacionais. Muita gente, principalmente entusiastas com pouca prática em programação, tem imaginado mil e uma formas de criar sistema de inteligência artificial usando para isto o Python. Ok, não estou aqui para criticar ou mesmo dizer que estas pessoas estão erradas. Porém, pense só no seguinte: Tais sistemas de inteligência artificial, fazem em seu cerne, o uso de um banco de dados. Seja ele não relacional, que acabamos de ver, ou um relacional que veremos daqui a pouco. Minha pergunta é: Por que tais bancos de dados são criados em Python, se você poderia fazer a mesma coisa usando o SQL?
Então apesar de toda a euforia em torno dos tais GPTs, fazendo com que muita gente passe a estudar Python, tentando criar algo parecido. Ou que no mínimo atenta a alguma necessidade específica. O mesmo poderia ser feito usando SQL. O grande detalhe é: Quanto de esforço você precisaria colocar, para fazer algo em uma ou em outra linguagem? Quando no passado, fiz uma serie de artigos falando sobre como criar um Expert Advisor que operasse de forma automática. Alguns me questionaram sobre o por que de eu ter feito aquilo. Mas pessoalmente, não vejo de fato nenhuma grande dificuldade em fazer algo daquele nível. Pois aquilo é algo super simples de ser construído.
Já um Expert Advisor que utilizaria um banco de dados, mantido e escrito em SQL para aprender a operar no mercado. Isto sim é algo que merece respeito. Pois apesar de ser algo igualmente simples de ser construído, é algo que envolve bastante conhecimento e dedicação. Ainda mais para fazer com que o Expert Advisor consiga aprender e criar o banco de dados da forma correta. Muito provavelmente, já deve existir algo assim. Um robô que usando o MetaTrader 5 junto com SQL, opere igual a um ser humano. Tendo toda uma subjetividade na tomada de decisão, se deve ou não operar, se deve comprar ou vender. Se um sinal é melhor do que outro. Enfim, este tipo de coisa pode nascer se você estudar as coisas corretas.
Muito bem, agora podemos ver o que seria um banco de dados relacional. Pois se você, tem algum conhecimento em programação, deve ter entendido como um banco de dados não relacional pode vir a surgir. Porém sem entender este primeiro, você não conseguirá entender o do tipo relacional. Novamente, o fato de usar ou não SQL, não faz a mínima diferença. O que faz a diferença é o como o banco está sendo criado.
Para entender o tipo relacional, precisamos voltar um pouco no tempo. Na verdade precisamos voltar em um artigo anterior, onde expliquei como você faz para modificar e excluir um registro do banco de dados. Bastará que você leia os artigos anteriores para encontrar o ponto do qual estou falando. Lá mostrei de forma bastante clara, que você precisa de algo para encontrar um determinado registro. Sem fazer uso deste algo, que é uma chave, você não encontraria a posição correta. Mas o que faz esta chave usada em um banco de dados relacional ser diferente de uma mesma chave usada em um banco não relacional? Uma das diferenças, é o fato de que no banco não relacional, aquela mesma chave não será única. Mas não é somente isto. Mas por hora, pense apenas neste ponto.
Aquela chave não irá se repetir, quando usamos um banco de dados relacional. Para isto normalmente a definimos como uma chave primária. Mas o fato de ela ser primária não é por conta de que ela não se repetirá. Você pode dizer ao SQL que em uma coluna, valores não poderão se repetir. E mesmo assim, isto não torna aqueles dados, ou registros, pertencentes a aquela coluna específica, em um conjunto de chaves primárias.
O que faz com que uma coluna tenha, ou seja, de chaves primárias é o fato de existir as chaves estrangeiras. Isto sim é que torna e garante que um banco de dados, seja ou não do tipo relacional. Isto por que, agora teremos uma relação entre uma chave presente um uma tabela, com uma outra chave presente em uma outra tabela. Este tipo de coisa é muito usada para gerar um tipo de banco de dados, onde você poderá fazer, ou deseja, que todos os registros sejam únicos. Mas principalmente, que de alguma forma, todos tenham alguma tipo de relação entre si. Criando algo que seria como um esquema de grafo muito similar ao mostrado na imagem abaixo.
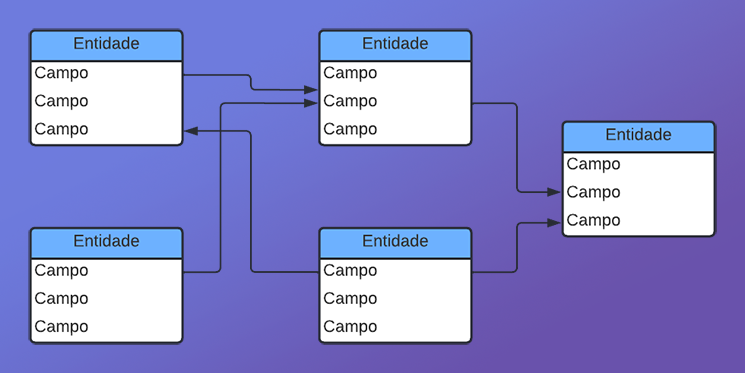
Talvez apenas observando esta imagem, isto de chave primária e chave estrangeira, não pareça fazer muito sentido. Mas, pense em um momento, se você criasse um banco de dados, sobre a sua vida particular. Este banco não precisaria de chave primária ou estrangeira. Porém, se você neste mesmo banco de dados começasse a adicionar, seus contatos pessoais. Sejam os de redes sociais ou pessoas próximas. Cada um destes contatos, teria uma chave que seria primária. Mas existirá pontos em que haverá coisas em comum, entre todos estes registros. Se você ao tentar manter este mesmo banco de dados, duplicasse estes pontos comuns, no momento de fazer alguma pesquisa cruzada, o processo seria muito mais lento e trabalhoso.
No entanto, se estes mesmos pontos em comum, fossem colocados em uma tabela especifica, você poderia usando uma outra chave, que neste caso é uma chave estrangeira. Cruzar as informações com muito mais facilidade. Agilizando assim tanto a pesquisa, quanto qualquer alteração que por ventura precise ser feita no banco de dados. E é assim que surge um banco de dados relacional. Ou seja, uma informação encontrada em um local, irá se ligar a outra informação colocada em outro local.
Considerações finais
Sei que o conteúdo deste artigo, pode soar muito abstrato e de difícil entendimento e compreensão. Porém quero ressaltar o fato de que os bancos de dados, como são definidos e utilizados nos dias atuais, não surgiram de uma hora para hora. Eles foram construídos e implementados aos poucos, no decorrer dos anos. Muitos de vocês, caros leitores, podem ter um nível de experiência muito superior ao meu, no que rege trabalhar com bancos de dados. Tendo assim uma visão diferente da minha.
Porém, como era preciso definir, e desenvolver alguma forma de explicar o motivo pelo qual os bancos de dados, são criados da forma como são criados. Explicar o por que o SQL tem o formato que tem. Mas principalmente, por que as chaves primárias e chaves estrangeiras vieram a surgir. Foi preciso deixar as coisas um pouco abstratas. Novamente, a questão sendo abordada apenas por meio de uma explicação, pode vim a parecer muito abstrata e sem uma justificativa válida.
Porém, como tenho interesse em mostrar, o básico sobre o assunto. Para que você, caro leitor, venha a conseguir fazer certos tipos de coisas. Isto sem precisar necessariamente se aprofundar muito em SQL. Precisamos entender este conceito, que é o das chaves primárias e chaves estrangeiras e como elas de fato funcionam. Isto por que entender de forma adequada tal conceito, fará grande uma diferença no momento de se criar um banco de dados. Mesmo que seja um apenas para pesquisa e aprendizado.
Se vamos começar a usar algo, devemos fazer isto da maneira correta. Aprender as coisas de forma, a não as entender realmente, não nos ajuda a nos desenvolver como profissionais. Pois como deixei claro, ou tentei deixar, durante este artigo. Não é o fato de você estar ou não usando SQL, que fará com que um arquivo, ou grupo de arquivos seja de fato um banco de dados relacional. Você pode simplesmente criar, o seu conjunto de procedimentos, instruções e rotinas a fim de criar um banco de dados. Não apenas para manipular um já existente. Mas literalmente criar um. E se você não compreender alguns dos conceitos envolvidos. Acabará por criar um sistema que ao logo do tempo se tornará insustentável.
Sei disto, pois durante muito tempo ignorei o uso do SQL, ou de implementações já existentes. Eu sempre teimava em criar minhas próprias soluções, e mesmo quando as mesmas funcionavam. Depois de um tempo, era preciso fazer algo que já existia no SQL. E todo aquele trabalho e tempo, poderia ter sido melhor utilizado, se eu simplesmente, passasse a usar uma solução já existente.
Então no próximo artigo, veremos de uma forma mais prática, como estas chaves são de fato usadas em um banco de dados. Talvez assim um conceito que neste momento é abstrato, se torne mais plausível e melhor entendido.
| Arquivo | Descrição |
|---|---|
| Experts\Expert Advisor.mq5 | Demonstra a interação entre o Chart Trade e o Expert Advisor (É necessário o Mouse Study para interação) |
| Indicators\Chart Trade.mq5 | Cria a janela para configuração da ordem a ser enviada (É necessário o Mouse Study para interação) |
| Indicators\Market Replay.mq5 | Cria os controles para interação com o serviço de replay/simulador (É necessário o Mouse Study para interação) |
| Indicators\Mouse Study.mq5 | Permite interação entre os controles gráficos e o usuário (Necessário tanto para operar o replay simulador, quanto no mercado real) |
| Services\Market Replay.mq5 | Cria e mantém o serviço de replay e simulação de mercado (Arquivo principal de todo o sistema) |
| Code VS C++\Servidor.cpp | Cria e mantém um soquete servidor criado em C++ (Versão Mini Chat) |
| Code in Python\Server.py | Cria e mantém um soquete em python para comunicação entre o MetaTrader 5 e o Excel |
| Indicators\Mini Chat.mq5 | Permite implementar um mini chat via indicador (Necessário uso de um servidor para funcionar) |
| Experts\Mini Chat.mq5 | Permite implementar um mini chat via Expert Advisor (Necessário uso de um servidor para funcionar) |
| Scripts\SQLite.mq5 | Demonstra uso de script SQL por meio do MQL5 |
| Files\Script 01.sql | Demonstra a criação de uma tabela simples, com chave estrangeira |
| Files\Script 02.sql | Demonstra a adição de valores em uma tabela |
Referência
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso