
Разработка трендовых торговых стратегий на основе машинного обучения

Введение
Существует несколько типов торговых стратегий, которые зарекомендовали себя в тейдинге. Одна из таких стратегий - стратегия возврата к среднему уже была рассмотрена в предыдущей статье. В настоящей статье я решил поделиться с читателем некоторыми идеями по поводу того, как можно использовать машинное обучение для создания трендовых стратегий или стратегий следования за трендом.
В данной статье будет использован аналогичный подход через кластеризацию данных для выделения рыночных режимов. Однако, сами разметчики сделок будут существенно отличаться. Поэтому, рекомендую сначала ознакомиться с первой статьей, после чего перейти к этой, как к логическому продолжению. Так вы сможете увидеть разницу между первым и вторым типом стратегий, а также разницу в разметке обучающих примеров. Ну что же, поехали!
Как можно делать разметку примеров для трендовых стратегий
Основное отличие трендовых стратегий от стратегий возврата к среднему заключается в том, что для трендовых стратегий важно точное определение текущего тренда, тогда как для стратегий возврата к среднему, достаточно, чтобы цены колебались вокруг некоего среднего значения и часто его пересекали. Можно сказать, что эти стратегии являются диаметрально противоположными. Если mean reversion подразумевает высокую вероятность смены направления изменения цены, то trend following подразумевает продолжение текущей тенденции.
Валютные курсы часто делятся на флэтовые и трендовые валютные пары. Конечно, это весьма условное разделение, поскольку на тех и на тех могут присутствовать как тренды, так и зоны консолидации. Здесь, скорее, разделение происходит по принципу того, как часто они находятся в том или ином состоянии. В данной статье мы не будем проводить подробное исследование вопроса, какие инструменты являются трендовыми на самом деле. Просто протестируем подход на валютной паре EURUSD, которая считается трендовой, в отличие от EURGBP, которая была рассмотрена в предыдущей статье в качестве флэтовой.
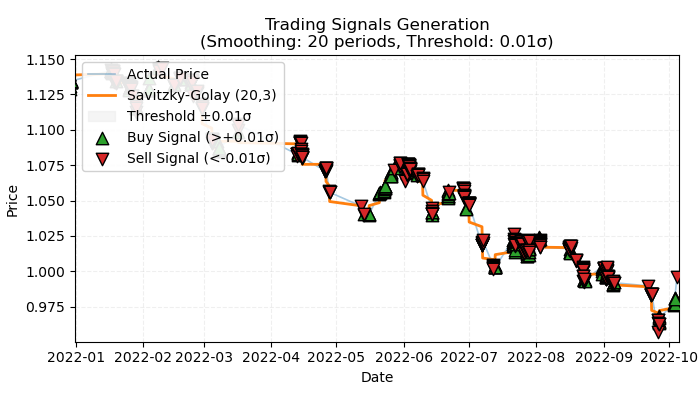
Рис 1. визуальное представление размеченных сделок по тренду
На Рис 1. изображен базовый принцип, который будет использоваться для разметки сделок по тренду. Для сглаживания краткосрочных шумовых колебаний, я снова использовал фильтр Савицкого-Голея, который был подробно рассмотрен в предыдущей статье. Но вместо того, чтобы считать отклонения цен от фильтра, как это было сделано в прошлый раз, теперь нас будет интересовать направление фильтра в качестве тренда. Если направление положительное, то ставится сделка на покупку, иначе — на продажу. Если направление не определено, то такие сделки не учитываются в процессе обучения. Функция разметки предполагает встроенный фильтр силы тренда или порог, который фильтрует незначительные тренды с учетом волатильности и будет рассмотрен ниже.
Базовый подход для разметки сделок по тренду
Давайте посмотрим, как выглядит функция разметки сделок под капотом, для полного понимания принципа ее работы:
@njit def calculate_labels_trend(normalized_trend, threshold): labels = np.empty(len(normalized_trend), dtype=np.float64) for i in range(len(normalized_trend)): if normalized_trend[i] > threshold: labels[i] = 0.0 # Buy (Up trend) elif normalized_trend[i] < -threshold: labels[i] = 1.0 # Sell (Down trend) else: labels[i] = 2.0 # No signal return labels def get_labels_trend(dataset, rolling=200, polyorder=3, threshold=0.5, vol_window=50) -> pd.DataFrame: smoothed_prices = savgol_filter(dataset['close'].values, window_length=rolling, polyorder=polyorder) trend = np.gradient(smoothed_prices) vol = dataset['close'].rolling(vol_window).std().values normalized_trend = np.where(vol != 0, trend / vol, np.nan) # Set NaN where vol is 0 labels = calculate_labels_trend(normalized_trend, threshold) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() # Remove rows with NaN return dataset
Функция get_labels_trend обрабатывает исходные данные — dataset, который содержит колонку "close" (цены закрытия) и возвращает датафрейм с добавленным столбцом размеченных меток.
Ключевые этапы разметки:
- Сглаживание цен. Используется фильтр Савицкого-Голея для сглаживания цен закрытия. В качестве параметров предусмотрены длина окна сглаживания и степень полинома. Цель — устранить шумы и выделить основной тренд.
smoothed_prices = savgol_filter(dataset['close'].values, window_length=rolling, polyorder=polyorder)- Расчет тренда. Вычисляется градиент сглаженных цен. Градиент показывает скорость изменения цены и ее направление. Положительный градиент означает растущий тренд, а отрицательный — падающий.
trend = np.gradient(smoothed_prices)
- Расчет волатильности. Волатильность рассчитывается как стандартное отклонение цен закрытия в скользящем окне. Это помогает оценить изменчивость цены для нормализации тренда.
vol = dataset['close'].rolling(vol_window).std().values- Нормализация тренда. Тренд делится на волатильность, чтобы учесть рыночную изменчивость.
normalized_trend = np.where(vol != 0, trend / vol, np.nan)- Генерация меток. На основе нормализованного тренда и порога, генерируются метки на покупку и продажу.
labels = calculate_labels_trend(normalized_trend, threshold)
- Использование порога. Это величина, которая отвечает за фильтрацию небольших отклонений градиента. Она подбирается эмпирическим способом, обычно в диапазоне 0.01 - 0.5. Если данные лежат внутри границ фильтра, то такие тренды игнорируются, как незначительные.
Возьмем данный подход к разметке за базис и напишем дополнительные разметчики сделок, чтобы иметь больше возможностей для экспериментов.
Разметка с ограничением на строго прибыльные сделки
Базовый подход предполагает наличие заведомо убыточных сделок, ведь они могут находиться в самом конце тренда, после которого происходит разворот. Это вполне соответствует реальным сигналам торговой системы, когда та может ошибаться. Важно лишь процентное соотношение прибыльных и убыточных сделок, чтобы оно всегда было в пользу прибыльных. Но можно избавиться от этого недостатка, размечая только прибыльные сделки и игнорируя убыточные. Это позволяет сгладить кривую баланса на тренировочных и, возможно, на тестовых данных. Ниже представлен код такой разметки.
@njit def calculate_labels_trend_with_profit(close, normalized_trend, threshold, markup, min_l, max_l): labels = np.empty(len(normalized_trend) - max_l, dtype=np.float64) for i in range(len(normalized_trend) - max_l): if normalized_trend[i] > threshold: # Проверяем условие для Buy rand = random.randint(min_l, max_l) future_pr = close[i + rand] if future_pr >= close[i] + markup: labels[i] = 0.0 # Buy (Profit reached) else: labels[i] = 2.0 # No profit elif normalized_trend[i] < -threshold: # Проверяем условие для Sell rand = random.randint(min_l, max_l) future_pr = close[i + rand] if future_pr <= close[i] - markup: labels[i] = 1.0 # Sell (Profit reached) else: labels[i] = 2.0 # No profit else: labels[i] = 2.0 # No signal return labels def get_labels_trend_with_profit(dataset, rolling=200, polyorder=3, threshold=0.5, vol_window=50, markup=0.00005, min_l=1, max_l=15) -> pd.DataFrame: # Smoothing and trend calculation smoothed_prices = savgol_filter(dataset['close'].values, window_length=rolling, polyorder=polyorder) trend = np.gradient(smoothed_prices) # Normalizing the trend by volatility vol = dataset['close'].rolling(vol_window).std().values normalized_trend = np.where(vol != 0, trend / vol, np.nan) # Removing NaN and synchronizing data valid_mask = ~np.isnan(normalized_trend) normalized_trend_clean = normalized_trend[valid_mask] close_clean = dataset['close'].values[valid_mask] dataset_clean = dataset[valid_mask].copy() # Generating labels labels = calculate_labels_trend_with_profit(close_clean, normalized_trend_clean, threshold, markup, min_l, max_l) # Trimming the dataset and adding labels dataset_clean = dataset_clean.iloc[:len(labels)].copy() dataset_clean['labels'] = labels # Filtering the results dataset_clean = dataset_clean.dropna() return dataset_clean
Основные отличия от базового подхода:
- Добавлен параметр min_l, который определяет минимальное количество баров в будущем, по которым измеряется будущее изменение цен по сравнению с текущим.
- Добавлен параметр max_l, который определяет максимальное количество баров в будущем, по которым измеряется будущее изменение цен по сравнению с текущими.
- Бар в будущем выбирается случайно в установленном этими параметрами диапазоне. Можно сделать фиксированную длину проверки, установив одинаковые значения.
- Если открытая сделка + n баров вперед принесла прибыль, то такая сделка добавляется в обучающий датасет, иначе размечается как 2.0 (нет сделки).
- Добавлен параметр markup, его следует задавать, как среднее спреда+комиссии+проскальзываний по торговому инструменту, можно с запасом. Это значение будет влиять на количество размеченных прибыльных сделок, чем оно больше, тем меньше сделок будут размечены как прибыльные, потому что они не прошли этот порог.
Разметка с возможностью выбора фильтра и с ограничением на строго прибыльные сделки
Как и в предыдущей статье, мы хотим иметь некоторый выбор фильтров, а не только один — Савицкого-Голея. Это позволит иметь больше вариаций разметок и лучше подстраивать торговую систему под особенности разных торговых инструментов. Предлагаю снова добавить простое скользящее среднее, экспоненциальное скользящее среднее и сплайн в качестве дополнительных фильтров. Просто для примера, потому что вы сможете добавить свои собственные, по аналогии.
@njit def calculate_labels_trend_different_filters(close, normalized_trend, threshold, markup, min_l, max_l): labels = np.empty(len(normalized_trend) - max_l, dtype=np.float64) for i in range(len(normalized_trend) - max_l): if normalized_trend[i] > threshold: # Проверяем условие для Buy rand = random.randint(min_l, max_l) future_pr = close[i + rand] if future_pr >= close[i] + markup: labels[i] = 0.0 # Buy (Profit reached) else: labels[i] = 2.0 # No profit elif normalized_trend[i] < -threshold: # Проверяем условие для Sell rand = random.randint(min_l, max_l) future_pr = close[i + rand] if future_pr <= close[i] - markup: labels[i] = 1.0 # Sell (Profit reached) else: labels[i] = 2.0 # No profit else: labels[i] = 2.0 # No signal return labels def get_labels_trend_with_profit_different_filters(dataset, method='savgol', rolling=200, polyorder=3, threshold=0.5, vol_window=50, markup=0.5, min_l=1, max_l=15) -> pd.DataFrame: # Smoothing and trend calculation close_prices = dataset['close'].values if method == 'savgol': smoothed_prices = savgol_filter(close_prices, window_length=rolling, polyorder=polyorder) elif method == 'spline': x = np.arange(len(close_prices)) spline = UnivariateSpline(x, close_prices, k=polyorder, s=rolling) smoothed_prices = spline(x) elif method == 'sma': smoothed_series = pd.Series(close_prices).rolling(window=rolling).mean() smoothed_prices = smoothed_series.values elif method == 'ema': smoothed_series = pd.Series(close_prices).ewm(span=rolling, adjust=False).mean() smoothed_prices = smoothed_series.values else: raise ValueError(f"Unknown smoothing method: {method}") trend = np.gradient(smoothed_prices) # Normalizing the trend by volatility vol = dataset['close'].rolling(vol_window).std().values normalized_trend = np.where(vol != 0, trend / vol, np.nan) # Removing NaN and synchronizing data valid_mask = ~np.isnan(normalized_trend) normalized_trend_clean = normalized_trend[valid_mask] close_clean = dataset['close'].values[valid_mask] dataset_clean = dataset[valid_mask].copy() # Generating labels labels = calculate_labels_trend_different_filters(close_clean, normalized_trend_clean, threshold, markup, min_l, max_l) # Trimming the dataset and adding labels dataset_clean = dataset_clean.iloc[:len(labels)].copy() dataset_clean['labels'] = labels # Filtering the results dataset_clean = dataset_clean.dropna() return dataset_clean
Основное изменение, по сравнению с предыдущим алгоритмом разметки, — это добавление параметра method, который может принимать следующие значения:
- savgol — фильтр Савицкого-Голея
- spline — интерполяция сплайнами
- sma — сглаживание простым скользящим средним
- ema — сглаживание экспоненциальным скользящим средним.
Разметка на основе фильтров с разными периодами и с ограничением на строго прибыльные сделки
Давайте усложним наше восприятие действительности и, как следствие, способ разметки сделок. Нет никакого запрета на использование только выбранного периода сглаживания. Одномоментно можно использовать сколько угодно фильтров одного типа с разными периодами и размечать сделки, когда хотя бы одно из условий сработало. Ниже представлен вариант такого сэмплера:
@njit def calculate_labels_trend_multi(close, normalized_trends, threshold, markup, min_l, max_l): num_periods = normalized_trends.shape[0] # Number of periods labels = np.empty(len(close) - max_l, dtype=np.float64) for i in range(len(close) - max_l): # Select a random number of bars forward once for all periods rand = np.random.randint(min_l, max_l + 1) buy_signals = 0 sell_signals = 0 # Check conditions for each period for j in range(num_periods): if normalized_trends[j, i] > threshold: if close[i + rand] >= close[i] + markup: buy_signals += 1 elif normalized_trends[j, i] < -threshold: if close[i + rand] <= close[i] - markup: sell_signals += 1 # Combine signals if buy_signals > 0 and sell_signals == 0: labels[i] = 0.0 # Buy elif sell_signals > 0 and buy_signals == 0: labels[i] = 1.0 # Sell else: labels[i] = 2.0 # No signal or conflict return labels def get_labels_trend_with_profit_multi(dataset, method='savgol', rolling_periods=[10, 20, 30], polyorder=3, threshold=0.5, vol_window=50, markup=0.5, min_l=1, max_l=15) -> pd.DataFrame: """ Generates labels for trading signals (Buy/Sell) based on the normalized trend, calculated for multiple smoothing periods. Args: dataset (pd.DataFrame): DataFrame with data, containing the 'close' column. method (str): Smoothing method ('savgol', 'spline', 'sma', 'ema'). rolling_periods (list): List of smoothing window sizes. Default is [200]. polyorder (int): Polynomial order for 'savgol' and 'spline' methods. threshold (float): Threshold for the normalized trend. vol_window (int): Window for volatility calculation. markup (float): Minimum profit to confirm the signal. min_l (int): Minimum number of bars forward. max_l (int): Maximum number of bars forward. Returns: pd.DataFrame: DataFrame with added 'labels' column: - 0.0: Buy - 1.0: Sell - 2.0: No signal """ close_prices = dataset['close'].values normalized_trends = [] # Calculate normalized trend for each period for rolling in rolling_periods: if method == 'savgol': smoothed_prices = savgol_filter(close_prices, window_length=rolling, polyorder=polyorder) elif method == 'spline': x = np.arange(len(close_prices)) spline = UnivariateSpline(x, close_prices, k=polyorder, s=rolling) smoothed_prices = spline(x) elif method == 'sma': smoothed_series = pd.Series(close_prices).rolling(window=rolling).mean() smoothed_prices = smoothed_series.values elif method == 'ema': smoothed_series = pd.Series(close_prices).ewm(span=rolling, adjust=False).mean() smoothed_prices = smoothed_series.values else: raise ValueError(f"Unknown smoothing method: {method}") trend = np.gradient(smoothed_prices) vol = pd.Series(close_prices).rolling(vol_window).std().values normalized_trend = np.where(vol != 0, trend / vol, np.nan) normalized_trends.append(normalized_trend) # Transform list into 2D array normalized_trends_array = np.vstack(normalized_trends) # Remove rows with NaN valid_mask = ~np.isnan(normalized_trends_array).any(axis=0) normalized_trends_clean = normalized_trends_array[:, valid_mask] close_clean = close_prices[valid_mask] dataset_clean = dataset[valid_mask].copy() # Generate labels labels = calculate_labels_trend_multi(close_clean, normalized_trends_clean, threshold, markup, min_l, max_l) # Trim data and add labels dataset_clean = dataset_clean.iloc[:len(labels)].copy() dataset_clean['labels'] = labels # Remove remaining NaN dataset_clean = dataset_clean.dropna() return dataset_clean
Желтым маркером я выделил основные моменты, на которые вы можете обратить внимание беглым взглядом:
- Функция разметки теперь принимает список произвольной длины, который содержит значения периодов сглаживания.
- В цикле осуществляется расчет фильтров для всех заданных периодов.
- В функции разметки участвуют градиенты трендов по всем фильтрам.
- Если хотя бы одно условие на покупку или продажу сработало с учетом того, что нет противоположных сигналов, размечается сделка.
Модуль labeling_lib.py пополнился четырьмя новыми сэмплерами:
def get_labels_trend(dataset, rolling=200, polyorder=3, threshold=0.5, vol_window=50) -> pd.DataFrame: def get_labels_trend_with_profit(dataset, rolling=200, polyorder=3, threshold=0.5, def get_labels_trend_with_profit_different_filters(dataset, method='savgol', rolling=200, polyorder=3, threshold=0.5, def get_labels_trend_with_profit_multi(dataset, method='savgol', rolling_periods=[10, 20, 30], polyorder=3, threshold=0.5,
Давайте остановимся на этих вариантах. Их вполне достаточно для тестирования основной идеи трендовой разметки.
Процесс обучения и тестирования моделей
Сама логика подготовки данных и обучения заимствована из прошлой статьи, поэтому не станем подробно описывать ее особенности. Но есть изменения, например, весь цикл обучения теперь вынесен в отдельную функцию processing, потому что появились новые возможности по управлению этим процессом.
Раньше сделки, размеченные как 2.0, просто удалялись из обучающего датасета и никак не участвовали в процессе обучения. Это могло приводить к потере информации, поскольку происходили пропуски в разметке сделок. Но как инкорпорировать эту информацию в торговую систему, если используется бинарный классификатор, а метки 2.0 (нет действия) представляют собой 3-й класс?
Вспомним, что в обучении участвуют два классификатора, первый из которых обучается предсказывать метки на покупку и продажу, а второй обучается предсказывать текущий рыночный режим (когда торговать, а когда нет). Значит, у нас есть возможность сделать миграцию примеров с 2.0 метками во вторую модель, и мы не будем терять информацию, как раньше, когда удаляли такие примеры.
def processing(iterations = 1, rolling = [10], threshold=0.01, polyorder=5, vol_window=100, use_meta_dilution = True): models = [] for i in range(iterations): data = clustering(dataset, n_clusters=hyper_params['n_clusters']) sorted_clusters = data['clusters'].unique() sorted_clusters.sort() for clust in sorted_clusters: clustered_data = data[data['clusters'] == clust].copy() if len(clustered_data) < 500: print('too few samples: {}'.format(len(clustered_data))) continue clustered_data = get_labels_trend_with_profit_multi( clustered_data, method='savgol', rolling_periods=rolling, polyorder=polyorder, threshold=threshold, vol_window=vol_window, min_l=1, max_l=15, markup=hyper_params['markup']) print(f'Iteration: {i}, Cluster: {clust}') clustered_data = clustered_data.drop(['close', 'clusters'], axis=1) meta_data = data.copy() meta_data['clusters'] = meta_data['clusters'].apply(lambda x: 1 if x == clust else 0) if use_meta_dilution: for dt in clustered_data.index: if clustered_data.loc[dt, 'labels'] == 2.0: if dt in meta_data.index: # Check if datetime exists in meta_data meta_data.loc[dt, 'clusters'] = 0 clustered_data = clustered_data.drop(clustered_data[clustered_data.labels == 2.0].index) # Синхронизация meta_data с bad_data models.append(fit_final_models(clustered_data, meta_data.drop(['close'], axis=1))) models.sort(key=lambda x: x[0]) return models
В коде маркером показано, что примеры, размеченные как 2.0 в датасете для первой модели, выбираются в датасете для второй модели по датам и строкам, соответсвующим этим датам, и в столбце clusters проставляются нули. Если вспомнить, что единицы разрешают торговлю, то вторая модель теперь будет предсказывать не только рыночный режим, но и плохие моменты входа в сделку по версии сэмплера сделок. Иными словами, вторая модель теперь будет предсказывать не только необходимый рыночный режим, но и нежелательные точки входа в рынок.
Предлагаю использовать сразу последний сэмплер, потому что он вобрал все самое лучшее и имеет гибкие настройки.
Проведем 10 циклов обучения с такими настройками:
hyper_params = {
'symbol': 'EURUSD_H1',
'export_path': '/Users/dmitrievsky/Library/Containers/com.isaacmarovitz.Whisky/Bottles/54CFA88F-36A3-47F7-915A-D09B24E89192/drive_c/Program Files/MetaTrader 5/MQL5/Include/Mean reversion/',
'model_number': 0,
'markup': 0.00010,
'stop_loss': 0.00500,
'take_profit': 0.00200,
'periods': [i for i in range(5, 300, 30)],
'periods_meta': [100],
'backward': datetime(2000, 1, 1),
'forward': datetime(2024, 1, 1),
'full forward': datetime(2026, 1, 1),
'n_clusters': 10,
'rolling': [10],
}Сама функция обучения вызывается таким образом:
dataset = get_features(get_prices()) models = processing(iterations = 10, threshold=0.001, polyorder=3, vol_window=100, use_meta_dilution = True)
В процессе обучения будут отображаться оценки R^2 для каждого прохода (кластера):
Iteration: 0, Cluster: 0 R2: 0.9837358133371028 Iteration: 0, Cluster: 1 R2: 0.9002342482016827 Iteration: 0, Cluster: 2 R2: 0.9755114279213657 Iteration: 0, Cluster: 3 R2: 0.9833351908595832 Iteration: 0, Cluster: 4 R2: 0.9537875370012954 Iteration: 0, Cluster: 5 R2: 0.9863566422346429 too few samples: 471 Iteration: 0, Cluster: 7 R2: 0.9852545217737659 Iteration: 0, Cluster: 8 R2: 0.9934196831544163
Протестируем лучшую модель из всего списка:
test_model(models[-1][1:], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], plt=True)
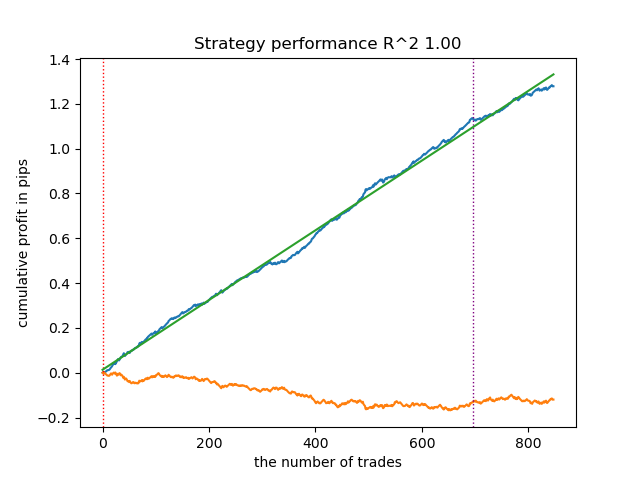
Рис 2. тестирование модели на обучающих и новых данных
Теперь можно вызвать функцию экспорта моделей в терминал Meta Trader 5.
export_model_to_ONNX(model = models[-1], symbol = hyper_params['symbol'], periods = hyper_params['periods'], periods_meta = hyper_params['periods_meta'], model_number = hyper_params['model_number'], export_path = hyper_params['export_path'])
Финальное тестирование моделей и общие замечания по алгоритму
Мой подход является универсальным, поэтому экспорт моделей в терминал осуществляется точно таким же способом, который был описан в предыдущей статье.
Давайте посмотрим на весь период обучение + тест и отдельно на тест. На рисунках видно, что на тренировочных данных кривая более гладкая, чем на тестовых данных, которые начинаются в 2024 году. Поскольку обучение проводилось с 2020 по 2024 год, тест приведен с 2019 года, чтобы показать, что на периоде перед обучением тоже не совсем все гладко.
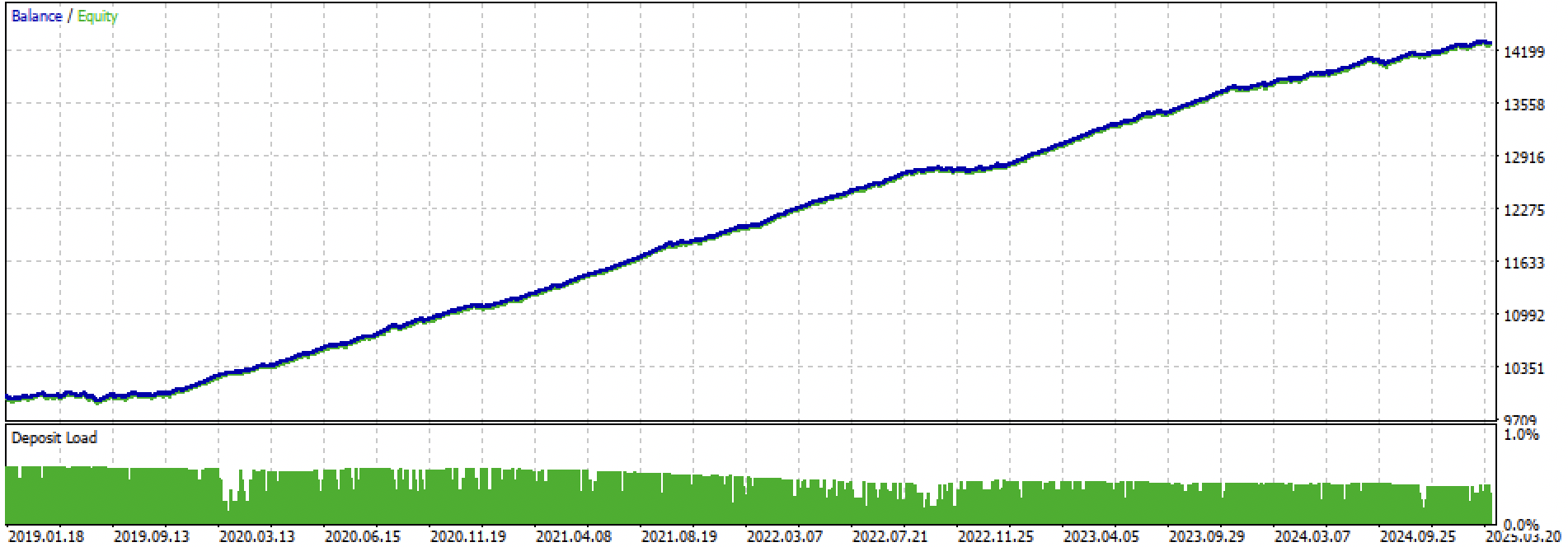
Рис 3. тестирование с 2019 по 2025 год.
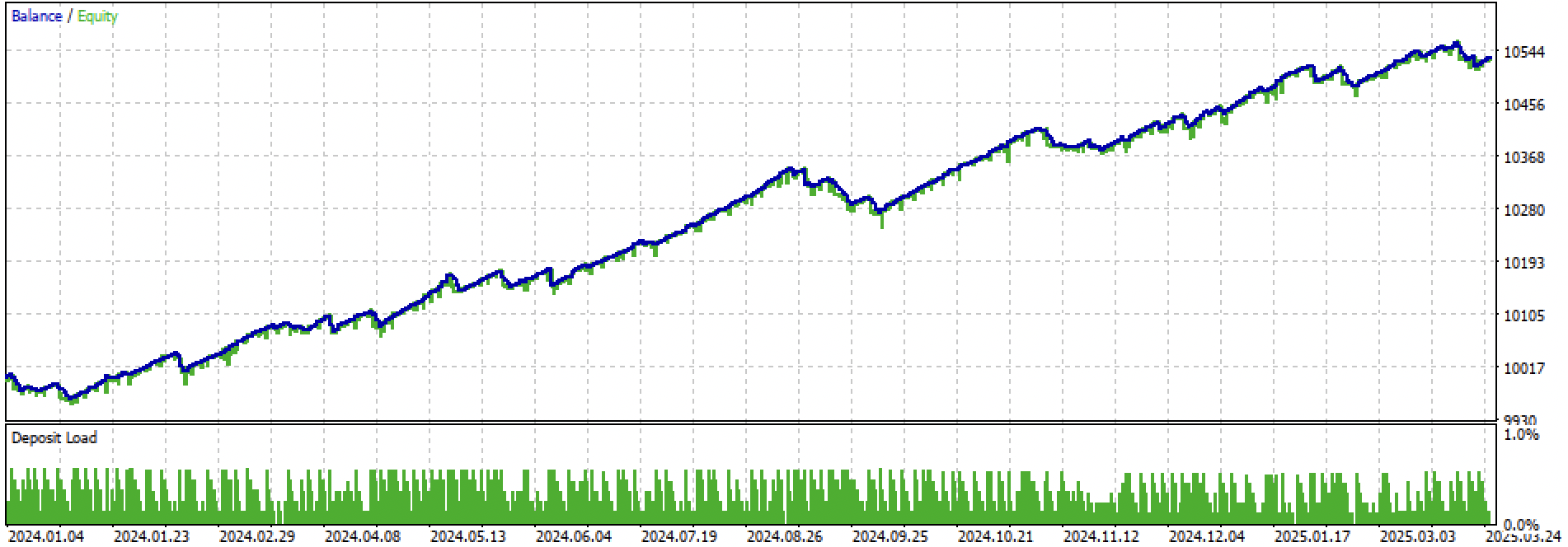
Рис 4. тестировние на форвард периоде с начала 2024 г до 27 марта 2025 г
Опираясь на проведенные эксперименты, я пришел к выводу, что трендовые стратегии более капризны в плане их работы на новых данных, либо данный подход плохо справляется с созданием таких стратегий на валютной паре EURUSD. Тем не менее, экспериментируя с настройкой гиперпараметров, можно получать достаточно неплохие модели. Недостатки частично компенсируются тем, что такие модели способны показывать хорошие результаты с очень коротким стоп-лоссом, например в 20 4-х значных пунктов. Это позволяет контролировать риски и вовремя выключать модели, когда они начинают выходить из строя.
Также я не смог выделить какой-то значимый сет гиперпараметров. Возникло ощущение, что алгоритм в принципе слабо ищет какие-то устойчивые закономерности, либо они просто отсутствуют.
Для борьбы с переобучением можно уменьшить сложность моделей в функции fit_final_models():
def fit_final_models(clustered, meta) -> list: # features for model\meta models. We learn main model only on filtered labels X, X_meta = clustered[clustered.columns[:-1]], meta[meta.columns[:-1]] X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] # labels for model\meta models y = clustered['labels'] y_meta = meta['clusters'] y = y.astype('int16') y_meta = y_meta.astype('int16') # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.7, test_size=0.3, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.7, test_size=0.3, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=100, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=15, plot=False) # learn meta model with train and validation subsets meta_model = CatBoostClassifier(iterations=100, custom_loss=['F1'], eval_metric='F1', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) meta_model.fit(train_X_m, train_y_m, eval_set=(test_X_m, test_y_m), early_stopping_rounds=15, plot=False) R2 = test_model([model, meta_model], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['full forward']) if math.isnan(R2): R2 = -1.0 print('R2 is fixed to -1.0') print('R2: ' + str(R2)) return [R2, model, meta_model]
Количество итераций отвечает за количество сплитов в модели и количество выбранных признаков. Изначально было 1000 итераций, снижаем их до 100. Ранний останов досрочно останавливает обучение, если ошибка классификации на валидационных данных не улучшается на протяжении 15 итераций.
Это дало более зашумленный баланс и сделало его более однородным, но менее красивым.
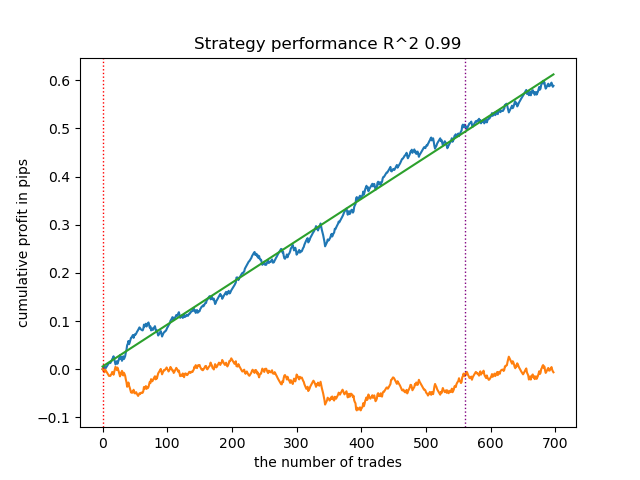
Рис 5. график баланса после уменьшения сложности моделей
Заключение
Трендовые стратегии на основе кластеризации и бинарной классификации создавать сложнее. Нужны новые инсайты на тему того, как это можно делать. Определенной проблемой видится выход цен финансовых активов за диапазон значений, на которых модель обучалась. В отличие от обучения на флэтовых инструментах, где цены на новых данных чаще соответствуют тем, на которых модель была обучена. Если же применять признаки на основе ценовых разниц, то модель снова демонстрирует плохую обобщающую способность.
Этой статьей я решил подытожить свои эксперименты с подходом через кластеризацию рыночных режимов и впереди вас ждут новые, еще более интересные идеи.
К статье прикреплены следующие материалы:
| Имя файла | Описание |
|---|---|
| labeling_lib.py | Обновленная библиотека сэмплеров |
| trend_following.py | Скрипт для обучения моделей |
| cat model_EURUSD_H1_0.onnx | Основная модель, папка include |
| catmodel_m_EURUSD_H1_0.onnx | Мета-модель, папка include |
| EURUSD_H1_ONNX_include_0.mqh | Заголовочный файл |
| trend_following.mq5 | Исходник торгового эксперта |
| trend_following.ex5 | Скомпилированный бот |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Кочерга - весна 2025?
Да, где-то в этот период
Да, где-то в этот период
Тогда результат неплохой. Весна 2025 - другой рынок.
Тогда результат неплохой. Весна 2025 - другой рынок.
Наверное евродоллар вообще в последнее время не очень хорошо предсказывается. Не получаются флэтовые/трендовые тс.
На хорошо трендовых (прим. золото) работают сделки только на покупку, как в последней статье. По барам, не скальпинг.
На евродолларе и однонаправленные не получаются.
Наверное евродоллар вообще в последнее время не очень хорошо предсказывается. Не получаются флэтовые/трендовые тс.
На хорошо трендовых (прим. золото) работают сделки только на покупку, как в последней статье. По барам, не скальпинг.
На евродолларе и однонаправленные не получаются.
Но если рынок поменяется, то тс умрет. без автоматического надсмотрщика - это уже полуручник
Но если рынок поменяется, то тс умрет. без автоматического надсмотрщика - это уже полуручник