取引におけるニューラルネットワーク:点群用Transformer (Pointformer)

はじめに
点群におけるオブジェクト検出は、多くの現実世界の応用において極めて重要です。画像と比較すると、点群は詳細な幾何情報を提供し、シーンの構造を効果的に捉えることができるためです。しかし、点群の不規則な構造は、効率的な表現学習をおこなううえで大きな課題となります。
Transformerベースのアーキテクチャは、自然言語処理の分野で顕著な成果を上げており、文脈に依存した表現の学習や入力シーケンス内の長距離依存関係のモデル化に優れています。自己アテンション機構を備えたTransformerは、順列不変性の要件を満たすと同時に、高い表現力を示します。しかし、Transformerをそのまま点群に適用する場合、入力サイズに対して計算コストが二乗的に増大するため、現実的ではありません。
この問題に対処するために、論文「3D Object Detection with Pointformer」で提案されたPointformer法では、セット構造のデータにおけるTransformerモデルの利点を活かすアプローチが導入されています。Pointformerは、マルチスケールのPointformerブロックから構成されるU-Net型の構造を採用しており、各Pointformerブロックは高い表現力を持ち、オブジェクト検出タスクに最適化されたTransformerベースのモジュールで構成されています。
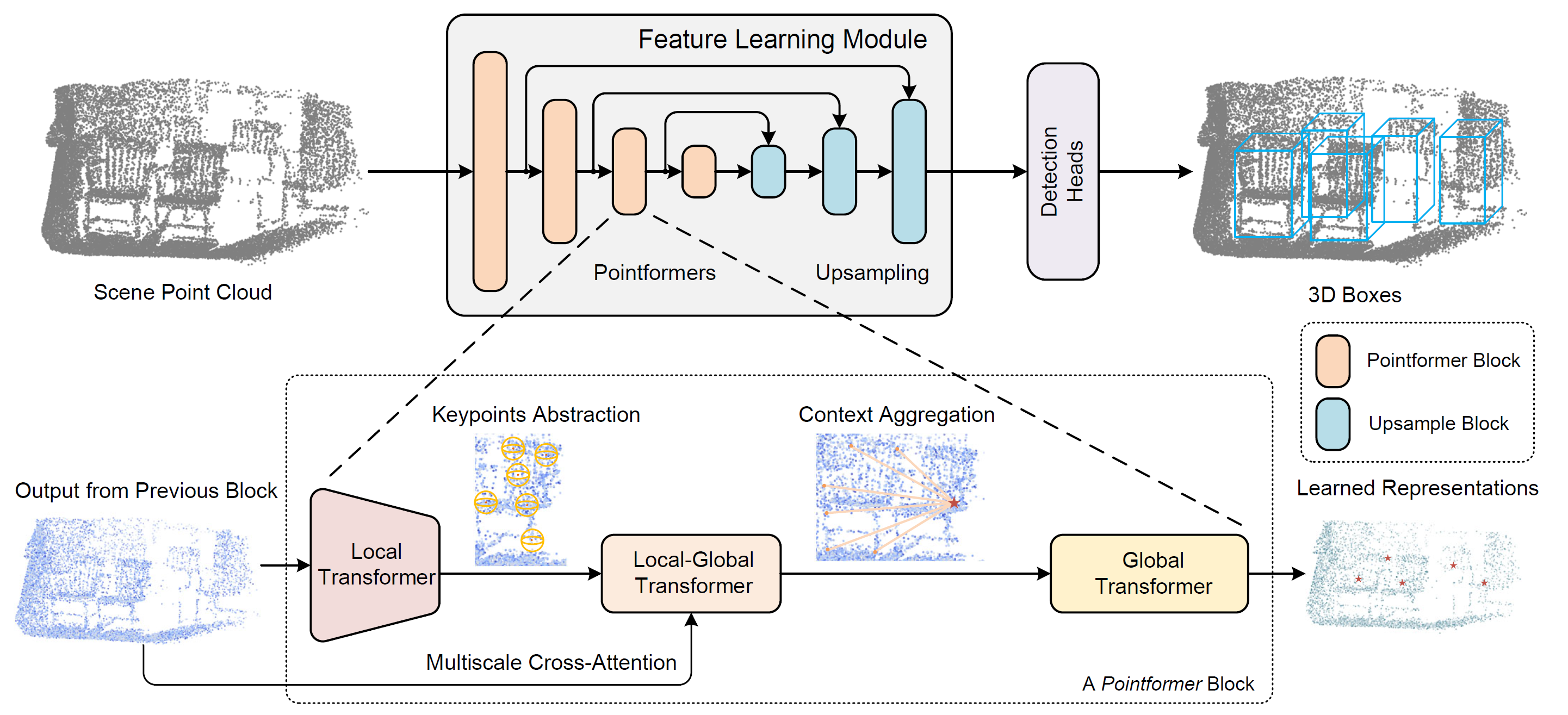
このアーキテクチャにおいて、著者は次の3種類のTransformerモジュールを組み合わせて使用しています。
- Local Transformer (LT):局所領域内の点同士の相互作用をモデル化し、オブジェクトレベルで文脈に応じた特徴量を学習します。
- Local-Global Transformer (LGT):局所特徴量と大域特徴量を、高解像度で統合する役割を果たします。
- Global Transformer (GT):シーン全体の文脈依存表現を捉えます。
これらのモジュールを組み合わせることで、Pointformerは局所的および大域的な依存関係を効果的にモデル化し、複数のオブジェクトが密集するような複雑なシーンにおいても、表現学習性能を大幅に向上させることに成功しています。
1. Pointformerアルゴリズム
点群を処理する際には、その不規則性、非順序性、およびサイズのばらつきを考慮することが不可欠です。Pointformerの著者は、点集合処理に特化したTransformerベースのモジュールを開発しました。これらのモジュールは、局所的な特徴量抽出の表現力を強化すると同時に、大域文脈情報を点表現に組み込むことを可能にします。
Pointformerブロックは、Local Transformer (LT)、Local-Global Transformer (LGT)、Global Transformer (GT)の3つのモジュールで構成されます。各ブロックはまずltから始まり、前層からの高解像度入力を受け取り、新たな低解像度点集合の特徴量を抽出します。続いて、lgtモジュールがマルチスケールのクロスアテンション機構を適用し、異なる解像度間の特徴量を統合します。最後に、GTモジュールがシーンレベルの文脈に応じた表現を獲得します。アップサンプリングには、pointnet++の特徴量伝播モジュールが採用されています。
点群シーンの階層的な表現を構築するために、pointformerでは異なる解像度で特徴量学習ブロックを構成する階層型手法が用いられています。まず、Farthest Point Sampling (FPS)により、重心となる点のサブセットを選択します。各重心に対して、指定した半径内の周囲の点を用いて局所近傍を定義します。これらの局所グループはシーケンス形式に整形されてTransformer層へ入力され、共有Transformerブロックがすべての局所領域に適用されます。pointformerブロック内にtransformer層を複数重ねることで、モジュールの表現力が高まり、より優れた特徴量表現が得られます。
また、この手法では隣接する点間の特徴量相関にも注目しています。重心よりも隣接点の方が有益な文脈情報を提供することがあり、局所領域内のすべての点間で情報交換をおこなうことで、すべての点を対等に扱い、より効果的な局所特徴量抽出が可能となります。
Farthest Point Sampling (FPS)は、点群システムにおいてほぼ均一なサンプル分布を得ながら入力全体の形状を保持できることから広く用いられています。これにより、限られた重心数で広範な空間カバレッジが実現されます。しかし、FPSには以下の2つの主な欠点があります。
- 外れ値に敏感であり、特に実世界の点群では不安定性が高くなる可能性があります。
- 元の点群の厳密な部分集合のみを選択するため、部分的に遮蔽されたオブジェクトや疎な点群では正確な幾何構造の再構築が難しくなります。
特に、ほとんどの点がオブジェクト表面上に存在することを踏まえると、後者の問題は深刻です。サンプリングベースの提案生成においては、提案の品質と実際のオブジェクトの存在との乖離が生じるおそれがあります。
この制約を克服するため、Pointformerの著者は自己アテンションマップに基づく座標補正モジュールを導入しました。このモジュールでは、まずTransformerの最終層の各アテンションヘッドから自己アテンションマップを抽出し、これを平均化します。その後、局所領域内の全点にアテンション重み付き平均を適用し、重心座標を洗練します。この処理により、重心座標が適応的にオブジェクトの真の中心に近づくようになります。このプロセスは、重心座標をオブジェクトの実際の中心に適応的に近づけます。
オブジェクト間の境界相関やシーンレベルの情報などの大域文脈も、オブジェクト検出タスクに役立ちます。pointformerは、transformerモジュールの特徴量を使用して、長距離の非局所依存関係をモデル化します。特に、Global Transformerモジュールは、点群全体にわたって情報を送信するように設計されています。すべての点は1つのグループに集められ、gtモジュールの初期データとして特徴量します。
シーンレベルでTransformerを使用すると、文脈に応じた表現を捉えられるようになり、さまざまなオブジェクト間での情報交換が容易になります。これらのグローバル表現は、少数の点のみで表現されるオブジェクトを検出する場合に特に役立ちます。
local-global transformerは、ltモジュールとgtモジュールによって抽出された局所特徴量とグローバル特徴量を組み合わせるための重要なモジュールでもあります。LGTは、マルチスケールのクロスアテンションメカニズムを使用して、低解像度の重心と高解像度の点間の関係を確立します。正式には、Transformerのクロスアテンションメカニズムを使用します。ltの結果はqueriesとして特徴量し、高解像度のgtの出力はkeyとvalueとして特徴量します。
位置エンコーディングはTransformerモデルの基本コンポーネントであり、入力シーケンスに位置情報を組み込む手段を提供します。Transformerを点群データに適合させる場合、点座標自体が非常に有益であり、局所の幾何学的構造をキャプチャする上で重要であるため、位置エンコードがさらに重要になります。
Pointformer法の著者による視覚化を以下に示します。
2.MQL5での実装
Pointformer法の理論的側面を確認した後、この記事の実践的な部分に進み、MQL5を使用して提案されたアプローチの解釈を実装します。
提案されたアプローチを詳しく調べてみると、PointNet++法との類似点がいくつかあることがわかります。どちらのアルゴリズムも、Farthest Point Sampling (FPS)メカニズムを使用して重心を形成します。どちらの手法も、基本的な操作は重心の周囲に点をグループ化することに基づいています。そのため、新しいCNeuronPointFormerクラスを構築するための親としてCNeuronPointNet2OCLオブジェクトを使用することにしました。その構造体を以下に示します。
class CNeuronPointFormer : public CNeuronPointNet2OCL { protected: CNeuronMLMHSparseAttention caLocalAttention[2]; CNeuronMLCrossAttentionMLKV caLocalGlobalAttention[2]; CNeuronMLMHAttentionMLKV caGlobalAttention[2]; CNeuronLearnabledPE caLocalPE[2]; CNeuronLearnabledPE caGlobalPE[2]; CNeuronBaseOCL cConcatenate; CNeuronConvOCL cScale; //--- CBufferFloat *cbTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override ; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronPointFormer(void) {}; ~CNeuronPointFormer(void) { delete cbTemp; } //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint output, bool use_tnets, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) override const { return defNeuronPointFormer; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
cneuronpointnet2oclでは、2つのスケールレベルを使用して局所特徴量を抽出しました。新しいクラスでは、同様のレベルのスケーリングを維持しますが、提案されたアテンションモジュールを使用することで、特徴量抽出の品質を新しいレベルに引き上げます。この改善はニューラル層の内部配列に反映されており、その目的は新しいCNeuronPointFormerクラスのメソッドの実装中に明らかになります。
内部コンポーネントの中には、動的に割り当てられたバッファが1つだけあります。これは、クラスデストラクタで適切に解放されます。クラスコンストラクタは空のままになります。すべての内部オブジェクトの初期化はInitメソッドで実行され、そのパラメータは親クラスからコピーされます。
bool CNeuronPointFormer::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint output, bool use_tnets, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronPointNet2OCL::Init(numOutputs, myIndex, open_cl, window, units_count, output, use_tnets, optimization_type, batch)) return false;
メソッドの本体では、まず親クラスから対応するメソッドを呼び出します。このメソッドは、受け取ったパラメータを制御し、継承されたオブジェクトを初期化します。
親クラスでは、局所 サブサンプリングの内部層を 2 つ作成します。これらの各層は、入力点群内のすべての点に対して 64 次元の特徴量ベクトルを出力します。
各局所サブサンプリング層の後に、Pointformer法の著者が提案したアテンションモジュールを挿入します。両方の層のアテンション モジュールのアーキテクチャは同一なので、ループ内でオブジェクトを初期化します。
for(int i = 0; i < 2; i++) { if(!caLocalAttention[i].Init(0, i*5, OpenCL, 64, 16, 4, units_count, 2, optimization, iBatch)) return false;
まず、CNeuronMLMHSparseAttentionブロックを使用して実装されるローカルアテンションモジュールを初期化します。
本手法は、オリジナルのPointformerアルゴリズムとは若干異なる点があることに留意してください。ただし、コアとなるロジックは維持されていると考えています。Pointformerにおいては、ローカルアテンションモジュールがローカル領域内の各点を共有コンテキスト特徴量で強化し、オブジェクト全体へのアテンション集中を可能にしています。実際、同一オブジェクトに属する点同士は強い相互依存性を示します。スパースアテンションを導入することで、固定されたローカル領域に縛られることなく、関係性の高い点に焦点を当てることが可能となります。これは、テクニカル分析において、価格が過去のさまざまな期間にわたって特定のしきい値と繰り返し相互作用する中で、サポートラインやレジスタンスラインを特定するプロセスに類似しています。
続いて、ローカルグローバルアテンションモジュールを初期化します。このモジュールは、元のデータに含まれるきめ細かな文脈情報をローカルオブジェクトの特徴量に統合します。
if(!caLocalGlobalAttention[i].Init(0, i*5+1, OpenCL, 64, 16, 4, 64, 2, units_count, units_count, 2, 2, optimization, iBatch)) return false;
グローバルアテンションブロックは、シーンレベルにおける文脈依存の表現を抽出するために使用されます。
if(!caGlobalAttention[i].Init(0, i*5+2, OpenCL, 64, 16, 4, 2, units_count, 2, 2, optimization, iBatch)) return false;
そしてもちろん、訓練可能な位置コーディングの内部層も追加します。ここでは、局地表現と大域表現に対して個別の位置エンコーディングを使用します。
if(!caLocalPE[i].Init(0, i*5+3, OpenCL, 64*units_count, optimization, iBatch)) return false; if(!caGlobalPE[i].Init(0, i*5+4, OpenCL, 64*units_count, optimization, iBatch)) return false; }
Pointformerの著者によって提案された重心座標の改良ブロックを、本手法では実装していないことは重要な留意点です。まず、私たちのPointNet++実装では、点群内の各点をその局地領域の重心として指定しています。したがって、点の座標を変更すると、シーン全体の構造が歪む可能性があります。次に、座標の改良に相当する機能の一部は、訓練可能な位置エンコーディング層によって本質的に処理されています。
特徴量抽出スケーリングに関する補足です。初期化された各モジュールは、異なる特徴量抽出スケールを明示的に示すものではありません。ただし、2点の違いがあります。親クラスでは局地サブサンプリングにおいて異なる半径を使用しており、本モジュール群では、局地アテンションに対して異なるスパース性のレベルを導入しています。
caLocalAttention[0].Sparse(0.1f); caLocalAttention[1].Sparse(0.3f);
2つのグローバルアテンションレベルの結果を1つのテンソルに連結します。
if(!cConcatenate.Init(0, 10, OpenCL, 128 * units_count, optimization, iBatch)) return false;
次に、そのテンソルの次元を、親クラスのメソッド内で初期化された大域点群記述子抽出ブロックの元のデータの次元レベルまで削減します。
if(!cScale.Init(0, 11, OpenCL, 128, 128, 64, units_count, 1, optimization, iBatch)) return false;
初期化メソッドの最後に、中間データを格納するためのバッファの作成を追加します。
if(!!cbTemp) delete cbTemp; cbTemp = new CBufferFloat(); if(!cbTemp || !cbTemp.BufferInit(caGlobalAttention[0].Neurons(), 0) || !cbTemp.BufferCreate(OpenCL)) return false; //--- return true; }
その後、操作の論理結果を呼び出し元プログラムに返して、メソッドを完了します。
開発の次の段階では、feedForwardメソッド内でフィードフォワードパスアルゴリズムを実装します。初期化メソッドとは異なり、ここでは親クラスの対応するメソッドに完全に依存することはできません。この新しいメソッドでは、継承されたコンポーネントと新しく導入されたコンポーネントの両方に関係する操作を統合する必要があります。
前と同様に、フォワードパスメソッドは、入力データオブジェクトへのポインタをパラメータの1つとして受け取ります。メソッド本体では、このポインタをすぐにローカル変数に格納します。
bool CNeuronPointFormer::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- LocalNet CNeuronBaseOCL *inputs = NeuronOCL;
通常、受け取ったポインタは必要がない限りローカル変数として保持しないようにしています。しかし本ケースでは、異なるスケールで動作する2つのネストされた特徴量抽出ブロックによって逐次処理がおこなわれるアルゴリズムを実装しているため、ローカル変数として扱うことでロジックが簡素化されます。これにより、反復中にポインタを異なるオブジェクトへ再割り当てすることが可能になります。
次に、上記のループの作成に進みます。
for(int i = 0; i < 2; i++) { if(!cTNetG || i > 0) { if(!caLocalPointNet[i].FeedForward(inputs)) return false; }
ループ内では、親クラスで宣言および初期化されたオブジェクトを使用して、まず局所サブサンプリング操作をおこないます。
重要な点は、親クラスのアルゴリズムには入力データを標準的な空間に射影するオプションが含まれていることです。この操作は、最初の局所サブサンプリング層の前にのみ適用されます。したがって、ループの最初で、この射影が必要かどうかを確認します。もし不要であれば、直接局所サブサンプリングステップに進みます。
射影が必要な場合は、まず射影行列を生成します。
else { if(!cTurnedG) return false; if(!cTNetG.FeedForward(inputs)) return false;
次に、元のデータの射影を実装します。
int window = (int)MathSqrt(cTNetG.Neurons()); if(IsStopped() || !MatMul(NeuronOCL.getOutput(), cTNetG.getOutput(), cTurnedG.getOutput(), NeuronOCL.Neurons() / window, window, window)) return false;
その後、初めて、局所データのサブサンプリングを実行します。
if(!caLocalPointNet[i].FeedForward(cTurnedG.AsObject())) return false; }
局所サブサンプリング層からの出力は、ローカルアテンションモジュールに直接渡されます。
//--- Local Attention if(!caLocalAttention[i].FeedForward(caLocalPointNet[i].AsObject())) return false;
位置エンコーディングなしでデータをローカルアテンションモジュールに渡すことに注意することが重要です。自己アテンションメカニズムは、入力要素の順序に対して本質的に不変であることを思い出してください。したがって、ローカルアテンションブロック内では、空間座標に依存することなく、相互に強い影響を与える要素を識別します。
一見、「座標に依存しないローカルアテンション」というフレーズは直感に反するように思えるかもしれません。なぜなら、ローカルアテンションは通常、空間的または位置的な制約を意味するからです。しかし、別の視点で考えてみましょう。価格チャートを例に取ってみましょう。情報は座標と特徴量の2つのカテゴリに分けることができます。この例では、時間が座標として機能し、価格レベルが特徴量を表します。座標(時間)を取り除くと、特徴空間内に点群が残ります。価格レベルが頻繁に現れる領域では、自然に点の密度が高くなります。これらの点は時間的に離れていることもありますが、そのような領域は多くの場合、支持レベルや抵抗レベルに対応します。この観点から、私たちのローカルアテンションモジュールは、局地特徴空間内で機能します。
このステップの後、ローカルアテンションモジュールの出力とローカルサブサンプリング層の出力の両方に位置エンコーディングを適用します。
//--- Position Encoder if(!caLocalPE[i].FeedForward(caLocalAttention[i].AsObject())) return false; if(!caGlobalPE[i].FeedForward(caLocalPointNet[i].AsObject())) return false;
次のステップでは、ローカルグローバルアテンションモジュールにおいて、ローカルアテンションのデータをオブジェクトの座標を考慮しつつ、大域的コンテキストの情報で強化します。
//--- Local to Global Attention if(!caLocalGlobalAttention[i].FeedForward(caLocalPE[i].AsObject(), caGlobalPE[i].getOutput())) return false;
そしてループ内の処理は、グローバルアテンションモジュールによって完了します。このモジュールでは、オブジェクトの情報がシーン全体の一般的なコンテキストによって強化されます。
//--- Global Attention if(!caGlobalAttention[i].FeedForward(caLocalGlobalAttention[i].AsObject())) return false; inputs = caGlobalAttention[i].AsObject(); }
ループの次の反復処理に進む前に、ローカル変数内のソースデータオブジェクトへのポインタを適切に更新します。
すべての内部層を順に処理するループを正常に完了した後、すべてのグローバルアテンションモジュールの結果を1つのテンソルに連結します。これにより、異なるスケールのオブジェクトの特徴量をさらに考慮することが可能になります。
if(!Concat(caGlobalAttention[0].getOutput(), caGlobalAttention[1].getOutput(), cConcatenate.getOutput(), 64, 64, cConcatenate.Neurons() / 128)) return false;
スケーリング層を使用して、連結されたテンソルのサイズを少し縮小してみましょう。
if(!cScale.FeedForward(cConcatenate.AsObject())) return false;
その後、受け取ったデータを、親クラスのさらに上位にあたるCNeuronPointNetOCLクラスのfeedForwardメソッド に渡します。大域点群記述子を生成するメカニズムを実装します。
if(!CNeuronPointNetOCL::feedForward(cScale.AsObject())) return false; //--- return true; }
すべての段階でプロセスを管理することを忘れてはなりません。メソッド内のすべての操作が正常に完了すると、その結果を示すブール値が呼び出し関数に返されます。
次に、バックプロパゲーションアルゴリズムの構築に進みます。ご存知のとおり、これには2つの主要なメソッドの実装が含まれます。
- calcInputGradients:最終結果への寄与に応じて、関連するすべてのコンポーネントに誤差勾配を分配する役割を担います。
- updateInputWeights:モデル内の訓練可能なパラメータを更新する役割を担います。
2つ目のメソッドを構築する際には、先ほど説明したフィードフォワードパスメソッドの構造をそのまま再利用できます。訓練可能なパラメータを含むコンポーネントに対するメソッド呼び出しの階層的な順序だけを残し、それぞれのフィードフォワード呼び出しを、対応するパラメータ更新メソッドに置き換えます。完成した実装は、確認用として添付ファイルに含まれています。
一方で、calcInputGradientscalcInputGradientsメソッドのアルゴリズムは、より慎重な設計が求められます。構造自体はフィードフォワードパスとほぼ同じですが、処理の順序が逆になります。ただし、モデル内部における情報伝達の並列性に伴い、いくつかの重要な注意点があります。
このメソッドは、誤差勾配を受け取るべき前段階の層オブジェクトへのポインタをパラメータとして受け取ります。そして、各データ要素がモデルの最終出力に与えた影響の大きさに応じて、勾配を適切に分配しなければなりません。
bool CNeuronPointFormer::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
メソッド本体では、受け取ったポインタの妥当性を即座に確認します。無効であれば、それ以上の操作を実行しても意味がありません。
このメソッドが呼び出される時点で、層出力レベルの誤差勾配はすでに対応するデータバッファに格納されていることを明記しておく必要があります。したがって、誤差勾配は、祖先クラスの対応するメソッドを呼び出すことで、内側のスケーリング層へと伝播されます。
if(!CNeuronPointNetOCL::calcInputGradients(cScale.AsObject())) return false;
次に、連結されたデータ層に誤差勾配を伝播します。
if(!cConcatenate.calcHiddenGradients(cScale.AsObject())) return false;
次に、それをグローバルアテンションの対応するモジュールに配布します。
if(!DeConcat(caGlobalAttention[0].getGradient(), caGlobalAttention[1].getGradient(), cConcatenate.getGradient(), 64, 64, cConcatenate.Neurons() / 128)) return false;
ここでは、すべての内部層のモジュールを通じて誤差勾配を一貫して渡す必要があります。これを実行するには、逆反復ループを作成します。
CNeuronBaseOCL *inputs = caGlobalAttention[0].AsObject(); for(int i = 1; i >= 0; i--) { //--- Global Attention if(!caLocalGlobalAttention[i].calcHiddenGradients(caGlobalAttention[i].AsObject())) return false;
このループでは、まずローカルグローバルアテンションモジュールのレベルで誤差勾配を定義します。次に、それを訓練可能な位置コーディングの層全体に配布します。
if(!caLocalPE[i].calcHiddenGradients(caLocalGlobalAttention[i].AsObject(), caGlobalPE[i].getOutput(), caGlobalPE[i].getGradient(), (ENUM_ACTIVATION)caGlobalPE[i].Activation())) return false;
その後、位置コーディングの対応する層からの誤差勾配をローカルアテンションモジュールと局所サブサンプリング層に転送します。
if(!caLocalAttention[i].calcHiddenGradients(caLocalPE[i].AsObject())) return false; if(!caLocalPointNet[i].calcHiddenGradients(caGlobalPE[i].AsObject())) return false;
さらに、ローカルアテンションモジュールは、ローカルサブサンプリング層の出力も入力データとして使用する点に注意が必要です。したがって、モジュールは自身に対応する誤差勾配の一部を、そのオブジェクトに対しても伝播させる必要があります。ただし、該当するデータバッファにはすでに位置エンコーディング層からの誤差勾配が格納されており、この情報を上書きして失ってはなりません。したがって、ローカルアテンションモジュールから誤差勾配を渡す前に、既存のバッファ内容を一時ストレージバッファに退避させる必要があります。
ここで重要なのは、データストレージバッファオブジェクトへの動的ポインタを意図的に作成したという点です。さらに、そのサイズは局所サブサンプリング層の誤差勾配バッファと同一に設定されています。これにより、データをコピーするのではなく、ポインタの単純な差し替えによって処理を効率化できます。
CBufferFloat *temp = caLocalPointNet[i].getGradient();
caLocalPointNet[i].SetGradient(cbTemp, false);
cbTemp = temp;
これで、以前に保存したデータが失われる心配なく、ローカルアテンションモジュールから誤差勾配を安全に転送できるようになりました。
if(!caLocalPointNet[i].calcHiddenGradients(caLocalAttention[i].AsObject())) return false; if(!SumAndNormilize(caLocalPointNet[i].getGradient(), cbTemp, caLocalPointNet[i].getGradient(), 64, false, 0, 0, 0, 1)) return false;
次に、2つのデータスレッドから得られた誤差勾配を合算します。
続いて、誤差勾配をソースデータレベルに伝播させる処理へと移りますが、ここにも注意すべき点があります。ループの反復状況に応じて、誤差勾配は、前の内部層にあるグローバルアテンションモジュール層、またはメソッドのパラメータとして渡されたソースデータオブジェクトのいずれかに伝播されます。後者の場合、処理の流れは親クラスのメソッドと同様です。一方、前者の場合には注意が必要です。というのも、分析対象の点群データから大域記述子を生成するモジュールからデータを分離する際に、すでに誤差勾配を一時保存しているためです。このケースでは、データバッファへのポインタを置き換えます。そのため、両者のバッファサイズは同一にです。
if(i > 0) { temp = inputs.getGradient(); inputs.SetGradient(cbTemp, false); cbTemp = temp; }
次に、正準空間の射影における誤差勾配を調整する必要性を確認します。そのような必要がない場合は、勾配を対応するオブジェクトにすぐに渡します。
if(!cTNetG || i > 0) { if(!inputs.calcHiddenGradients(caLocalPointNet[i].AsObject())) return false; }
ただし、フィードフォワードパス中に正準空間への射影が実行された場合は、まず誤差勾配を射影層モジュールのレベルに渡します。
else { if(!cTurnedG) return false; if(!cTurnedG.calcHiddenGradients(caLocalPointNet[i].AsObject())) return false;
次に、誤差勾配を元のデータと射影行列に分散します。
int window = (int)MathSqrt(cTNetG.Neurons()); if(IsStopped() || !MatMulGrad(inputs.getOutput(), inputs.getGradient(), cTNetG.getOutput(), cTNetG.getGradient(), cTurnedG.getGradient(), inputs.Neurons() / window, window, window)) return false;
直交行列からの偏差誤差に合わせて射影行列の勾配を調整します。
if(!OrthoganalLoss(cTNetG, true)) return false;
ここで、2つのデータスレッドからの誤差勾配を保持するために、データバッファスワッピング操作も整理します。
CBufferFloat *temp = inputs.getGradient(); inputs.SetGradient(cTurnedG.getGradient(), false); cTurnedG.SetGradient(temp, false);
射影行列生成モジュールから正準空間への誤差勾配を、元のデータのレベルまで伝播します。
if(!inputs.calcHiddenGradients(cTNetG.AsObject())) return false;
次に、2つのデータスレッドからの初期データレベルでの誤差勾配を合算します。
if(!SumAndNormilize(inputs.getGradient(), cTurnedG.getGradient(), inputs.getGradient(), 1, false, 0, 0, 0, 1)) return false; }
次に、他の情報スレッドからの誤差勾配を再度加算する必要があるかどうかを判断し、ローカル変数内のポインタをソースデータオブジェクトに置き換えます。その後、ループの次の反復処理へと進みます。
if(i > 0) { if(!SumAndNormilize(inputs.getGradient(), cbTemp, inputs.getGradient(), 64, false, 0, 0, 0, 1)) return false; inputs = caGlobalAttention[i - 1].AsObject(); } else inputs = NeuronOCL; } //--- return true; }
すべての反復処理が完了した後、勾配分配処理が正常に完了したことを示すブール値を呼び出し元関数に返し、メソッドの実行を終了します。
これにて、Pointformer法の提案者によるアプローチを統合した、新たに開発したCNeuronPointFormerクラスにおける各メソッドのアルゴリズム実装の概要説明を完了します。このクラスとそれに関連するすべてのメソッドの完全なコードは添付ファイルで入手できます。
続いて、本クラスを統合したモデルアーキテクチャについて説明します。今回の統合は比較的単純です。以前と同様に、本クラスは環境状態情報を処理するエンコーダモデルに組み込まれます。使用されているのは、前回の記事で紹介したのと同じ基本アーキテクチャです。モデル構造自体にはほとんど変更がなく、親クラスから継承されたレイヤタイプのみを本クラスに置き換え、その他のパラメータはすべて維持されています。この変更によって、ActorモデルやCriticモデルのアーキテクチャ、学習アルゴリズム、あるいは環境との相互作用の仕組みに変更を加える必要はありません。これらの要素はすべて、既存のものを変更せずに再利用しています。したがって、本記事ではそれらについての詳細な説明は省略します。本記事の作成に使用されたすべてのモデル構成とプログラムの完全なソースコードは、添付ファイルに含まれています。
3.テスト
私たちは、Pointformerの著者が提案した手法をMQL5を使用して実装するために多大な作業をおこなってきました。
この記事で紹介している実装は、元のPointformerアルゴリズムとはいくつかの点で異なることに注意する必要があります。そのため、得られた結果は、元の研究で報告されたものとは若干異なる可能性があります。
それでは、実装の結果を見ていきましょう。前回の研究と同様に、2023年のEURUSDの実際の履歴データ(H1時間枠)を使用してモデルを訓練しました。すべてのインジケーターパラメータはデフォルト設定のままとしました。
最初に、エキスパートアドバイザー(EA)「...\PointFormer\Study.mq5」をリアルタイムモードで実行し、モデルの反復的なオフライン訓練をおこないました。このEAは取引操作をおこなうことはありません。そのロジックは、モデルの訓練にのみ焦点を当てています。
最初の訓練の反復は、以前の研究で収集されたモデル訓練データを使用しておこないます。訓練データの構造とパラメータには変更はありません。
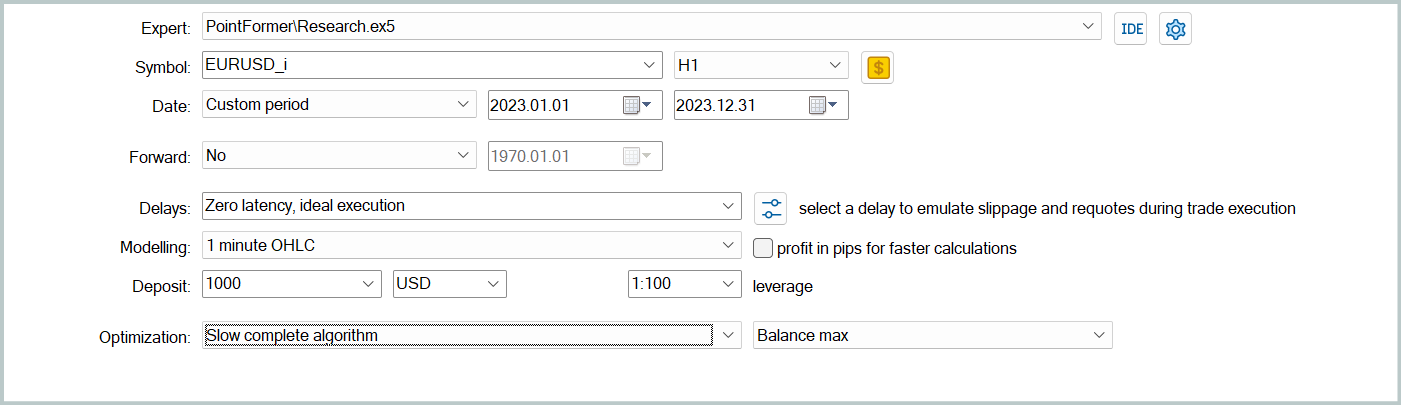
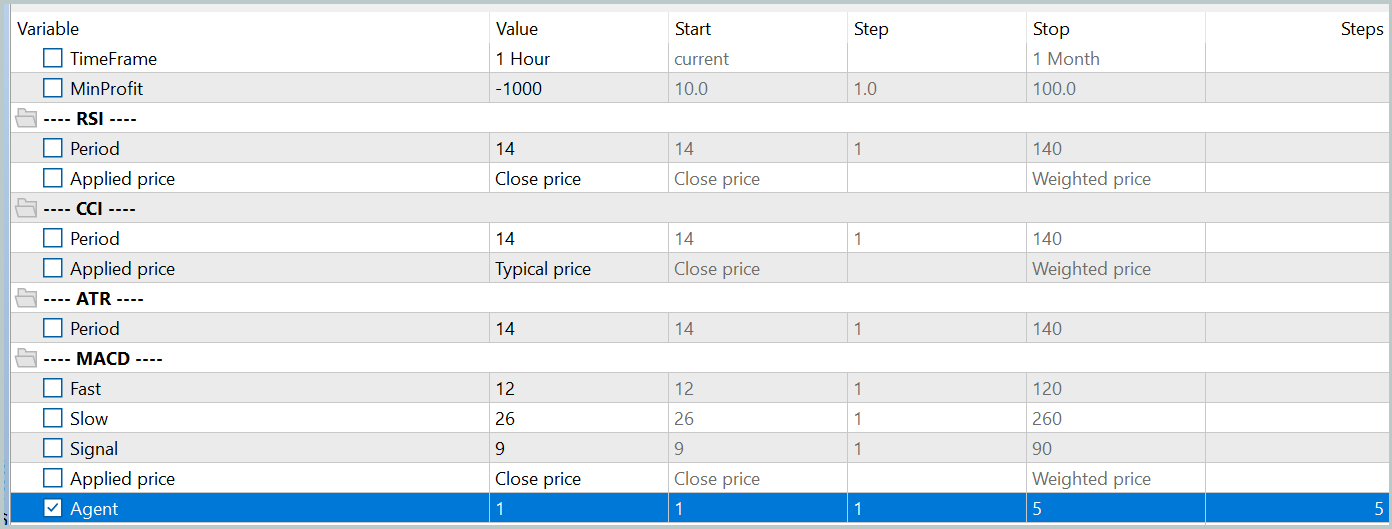
次に、Actorの現在の行動方針をより正確に反映させるために訓練データセットを更新します。これにより、訓練中の動作をより適切に評価し、方針の最適化方向をより良く調整できるようになります。このために、環境相互作用EA「...\PointFormer\Research.mq5」を使用して、ストラテジーテスターで低速最適化モードを起動します。
その後、モデルの訓練プロセスを繰り返します。
モデルの訓練と訓練データセットの更新は、複数のサイクルにわたって反復的に実行されます。訓練が完了したと見なせる良い指標は、データセット更新の最終反復におけるすべてのパスで許容できる結果が得られることです。
個々のパスの結果に若干の相違が生じても許容される点に留意してください。これは、Actorが確率的方針を採用しており、学習した行動範囲内で行動に自然とランダム性が伴うためです。モデルの訓練が進むにつれて、この確率的な動作は通常減少します。しかし、方針全体の収益性に大きな影響を与えない限り、行動の多少の変動は許容されます。
モデルの訓練とデータセット更新を数回繰り返した後、訓練データセットおよびテストデータセットの両方で利益を生み出すことができる方針を取得することに成功しました。
その後、MetaTrader 5のストラテジーテスターを使用して、訓練済みモデルのパフォーマンスを評価しました。テストは2024年1月の履歴データを使用して実行し、他のすべてのパラメータは変更しませんでした。以下にそのテスト結果を示します。
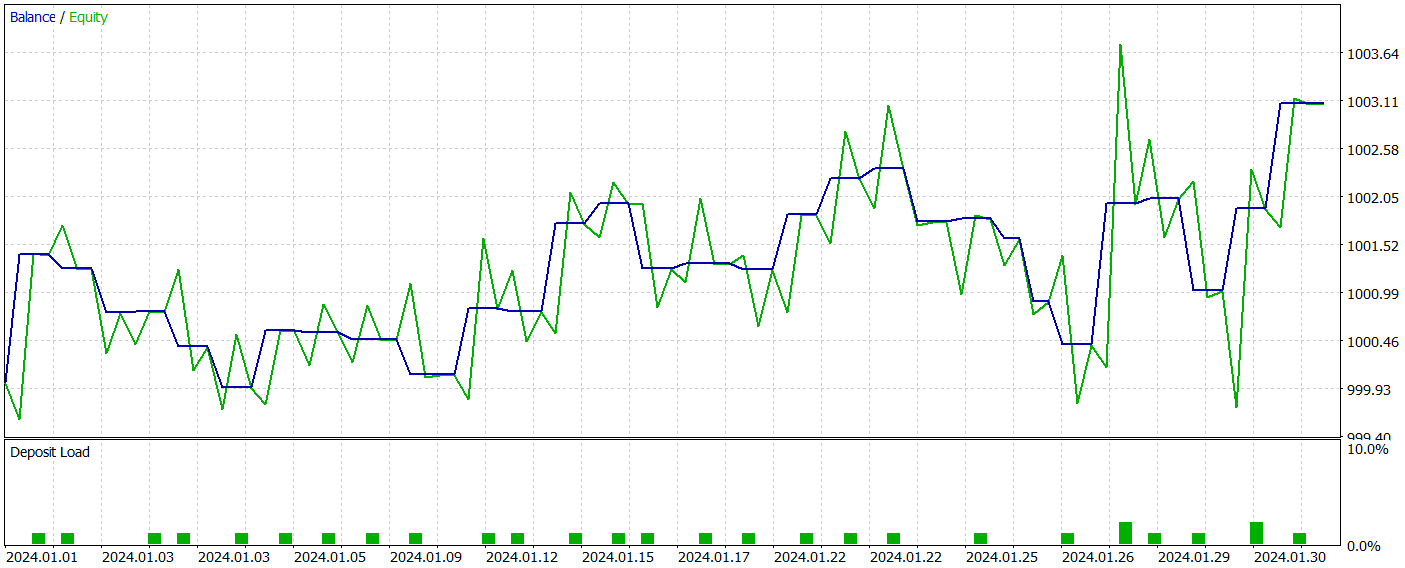
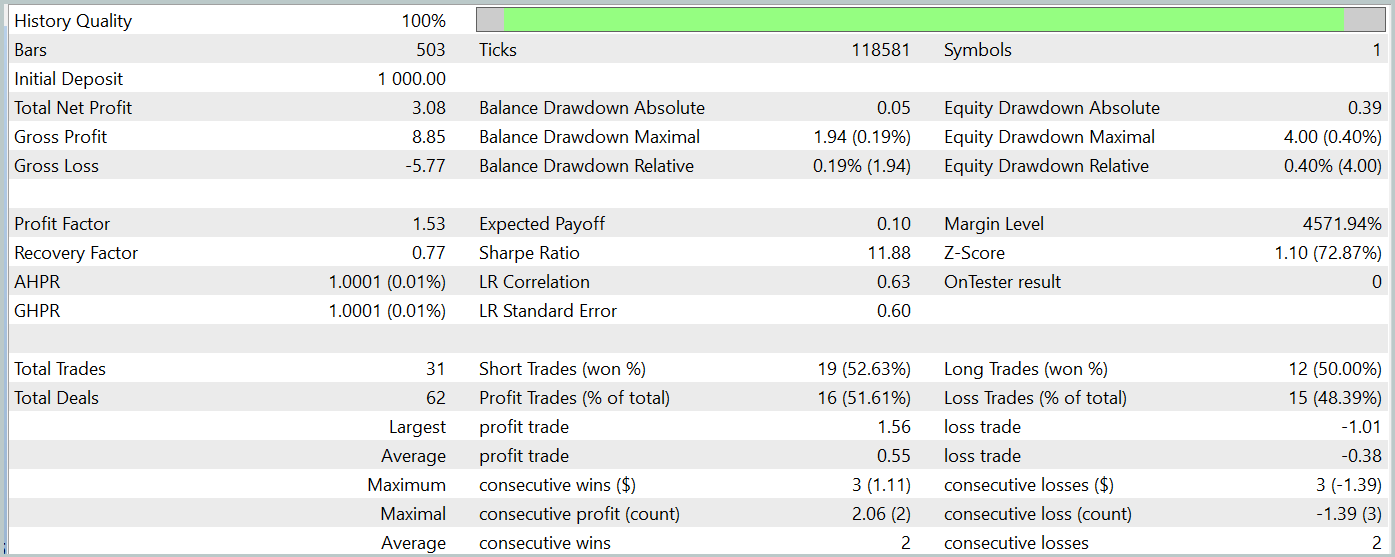
テスト期間中、訓練済みのモデルは合計31件の取引を実行し、そのうち半分は利益で終了しました。特に、最大および平均の利益のある取引の値が損失のある取引の値と比較してほぼ50%高く、これによりプロフィットファクターは1.53となりました。エクイティカーブに上昇傾向が見られたものの、取引回数が限られているため、長期的な視野でのモデルの有効性について明確な結論を導き出すことはできません。
結論
この記事では、点群データを操作するための新しいアーキテクチャを導入するPointformerメソッドについて説明しました。提案されたアルゴリズムは、ローカルTransformersとグローバルTransformerを組み合わせることで、多次元データからローカル空間パターンとグローバル空間パターンの両方を効果的に抽出できるようにします。PointformerPointformerは、アテンションメカニズムを用いて空間コンテキストに基づく情報処理をおこない、各点の相対的な重要性を考慮しながら学習をサポートします。
実践的な部分では、MQL5言語を用いて提案手法の実装をおこないました。説明したアルゴリズムに基づいてモデルを訓練し、テストした結果、この方法が複雑なデータ構造の分析において潜在的な可能性を示すことができました。
ただし、財務データ分析のコンテキストにおけるPointformerの機能をより深く理解するためには、さらなる調査と最適化が必要であることを認識することが重要です。
参照文献
記事で使用されているプログラム
| # | ファイル名 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 事例収集のためのEA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | Test.mq5 | EA | モデルテストEA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | ライブラリ | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/15820
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索