取引におけるニューラルネットワーク:Superpoint Transformer (SPFormer)

はじめに
オブジェクトセグメンテーションは、スパースな点群内の物体を検出するだけでなく、それぞれの物体に対して正確なマスクを提供することを目的とした、シーン理解における複雑なタスクです。
近年の手法は以下の2種類に大別されます。
- 仮定に基づくアプローチ
- クラスタリングベースのアプローチ
仮定ベースの手法では、3Dオブジェクトセグメンテーションをトップダウン型のパイプラインとして扱います。まず領域提案を生成し、その後、それらの領域内でオブジェクトのマスクを決定します。しかし、こうした手法は点群のスパース性によりうまく機能しないことが多くあります。3D空間ではバウンディングボックスに高い自由度があるため、近似が困難です。また、点群は通常、オブジェクト表面の一部にしか存在しないため、幾何学的中心の特定が難しくなります。低品質な領域提案は、ブロックベースの二部マッチングに悪影響を与え、モデルの性能をさらに低下させます。
一方、クラスタリングベースの手法はボトムアップ型のパイプラインに従い、各点のセマンティックラベルやインスタンス中心のオフセットを予測し、それらの情報をもとに点群をインスタンスに集約します。しかし、これらの手法にも課題があります。セマンティックセグメンテーション結果への依存により、インスタンスの予測精度が低下する可能性があるほか、中間データの集約処理により学習および推論の所要時間が増加します。
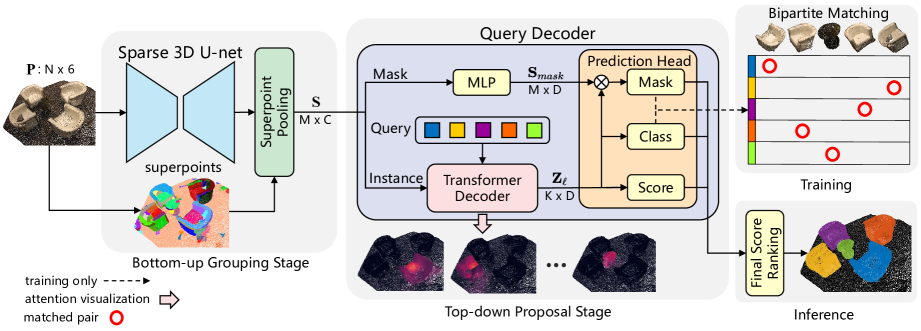
こうした課題を解決し、両手法の利点を統合するために、論文「Superpoint Transformer for 3D Scene Instance Segmentation」の著者は、Superpoint Transformer (SPFormer)というエンドツーエンドの2段階型3Dオブジェクトセグメンテーション手法を提案しました。SPFormerは、点群からボトムアップに潜在的オブジェクトをSuperpointにグループ化し、クエリベースのトップダウンアプローチでインスタンスを予測します。
ボトムアップグループ化の段階では、スパース3D U-Netを用いて点レベルの特徴量を抽出し、ポイントプーリング層によって候補となる点群をスーパーポイントにグループ化します。これらのスーパーポイントは、幾何学的パターンをもとに、近接かつ類似した点を統一的に表現する単位です。この処理により、セマンティックラベルや中心距離といった間接的な教師信号が不要になります。著者は、スーパーポイントを3Dシーンにおける中間的な表現とみなし、インスタンスラベルのみでモデルを学習させています。
トップダウン提案段階では、新たに設計されたTransformerデコーダが導入され、学習可能なクエリベクトルを通じてスーパーポイントからインスタンスを予測します。クエリはスーパーポイントに対するクロスアテンションを用いてインスタンス情報を取得し、インスタンス情報とスーパーポイント機能が強化されたクエリベクトルを使用して、デコーダーはクラスラベル、信頼スコア、およびインスタンスマスクを直接予測します。また、スーパーポイントマスクに基づく二部マッチングを用いることで、手作業による中間集約処理を排除し、エンドツーエンドの訓練を可能にしています。さらに、後処理も不要なため、モデルの効率性も大幅に向上しています。
1. SPFormerアルゴリズム
著者ら提案するSPFormerモデルのアーキテクチャは、論理的に複数のブロックに分かれています。まず、スパース3D U-netを用いて、ボトムアップで点レベルのオブジェクト特徴量を抽出します。入力点群にN個の点が含まれていると仮定し、各点はRGBの色情報とXYZの座標で特徴付けられます。生の点群データを正規化するために、著者は点群をボクセル化し、スパース畳み込みで構成されたU-Netスタイルのバックボーンを使って、点特徴量P′を抽出する手法を提案しています。クラスタリングベースの手法とは異なり、このアプローチでは追加のセマンティックブランチを導入していません。
統一されたフレームワークを構築するため、SPFormerの著者は事前に計算された点情報に基づいて、抽出された点特徴P′をスーパーポイントプーリング層へ直接入力します。このスーパーポイントプーリング層では、各スーパーポイント内の点群を平均化することでS個のスーパーポイントを生成します。注目すべきは、このスーパーポイントプーリング層が元の点群を効果的にダウンサンプリングすることで、後続の処理にかかる計算コストを大幅に削減し、モデル全体の表現効率も向上させている点です。
クエリデコーダは インスタンスとマスクの2つのブランチで構成されています。マスクブランチでは、インスタンスマスク𝐒maskの予測を支援する特徴を抽出するために、シンプルな多層パーセプトロン(MLP)が使用されます。インスタンスブランチは、複数のTransformerデコーダ層から成り、学習可能なクエリベクトルをスーパーポイントに対するクロスアテンションを通じてデコードします。
学習可能なクエリベクトルがK個あると仮定、各Transformerデコーダ層におけるクエリベクトルの特性をZlとして事前に定義します。
スーパーポイントの形状やサイズが不規則かつ可変であることを踏まえ、著者は入力データのばらつきを処理するためのTransformer構造を導入しました。スーパーポイント特徴量と学習可能なクエリベクトルが、Transformerデコーダへの入力となります。修正されたTransformerデコーダ層のの綿密に設計されたアーキテクチャは、以下の図に示されています。
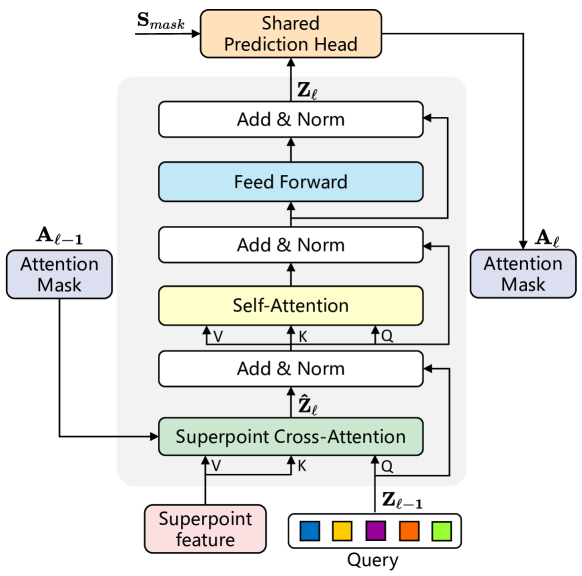
SPFormerのクエリベクトルは訓練前にランダムに初期化され、各点群に対するインスタンス固有の情報は、スーパーポイントとのクロスアテンションを通じてのみ取得されます。その結果、提案されたTransformerデコーダ層では、従来のTransformerデコーダと比較して自己アテンション層とクロスアテンション層の順序が逆転されており、標準的なアーキテクチャが変更されています。さらに、入力はスーパーポイントの特徴量で構成されているため、位置エンコーディングは省略されています。
スーパーポイントクロスアテンションを通じて文脈情報を取得するために、クエリiに対するスーパーポイントjの影響を示すアテンションマスクAijが適用されます。マスクブランチから出力される予測スーパーポイントマスクMlに基づき、著者が経験的に決定したしきい値τ=0.5を用いたフィルタリングにより、スーパーポイントアテンションマスクAlが計算されます。
Transformerデコーダ層を積み重ねることで、スーパーポイントAlアテンションマスクはクロスアテンションを動的に制限し、前景インスタンス領域に焦点を当てるようになります。
インスタンスブランチのクエリベクトルZlを用いて、著者は2つの独立したMLPを使用し、各クエリベクトルに対して分類ラベルと品質スコアを予測します。特に、「オブジェクトなし」という予測を追加することで、二部マッチングの際に信頼スコアを明示的に割り当て、一致しなかったすべてのクエリを負のサンプルとして扱います。
さらに、提案のランキングはインスタンスセグメンテーションの性能に大きな影響を与えるにもかかわらず、1対1のマッチングスキームではほとんどの提案がバックグラウンドとして扱われるため、ランキングの不整合が発生する可能性があります。これを緩和するため、著者は各スーパーポイントマスクの予測品質を評価するスコアリングブランチを導入し、この種のバイアスを是正しています。
また、Transformerベースのアーキテクチャでは収束が遅いことが多いため、著者は各Transformerデコーダ層の出力をすべて共有の予測ヘッドにルーティングし、各層でインスタンス提案を生成します。訓練時には、各デコーダ層の出力に対してグラウンドトゥルースの信頼スコアが割り当てられます。このアプローチにより、モデルの性能が向上し、クエリベクトルが層を通じてより効果的に進化するようになります。
推論時には、生の入力点群に対して、SPFormerはK個のオブジェクトインスタンスをそのクラスラベルおよび対応するスーパーポイントマスクとともに直接予測します。最終的なマスクスコアは、各予測マスク内で値が0.5を超えるスーパーポイントの確率の平均として算出されます SPFormerは後処理において非最大抑制に依存しないため、高速な推論が可能です。
著者が提示したSPFormerアーキテクチャの視覚的な表現を以下に示します。
2.MQL5での実装
SPFormer法の理論的側面を確認した後、この記事の実践的な部分に進み、MQL5を使用して提案されたアプローチの解釈を実装します。今日はやるべきことがたくさんあります。それでは始めましょう。
2.1 OpenCLプログラムの拡張
まずは、既存のOpenCLプログラムを拡張するところから始めます。SPFormer法の著者は、予測されたオブジェクトマスクに基づく新たなマスキングアルゴリズムを提案しました。主なアイデアは、各クエリを関連するスーパーポイントとだけマッチさせるというもので、これは以前使用していた標準的なTransformerにおける位置ベースのアプローチとは大きく異なります。そのため、クロスアテンションおよびバックプロパゲーション用の新しいカーネルを開発する必要があります。まずは、フィードフォワード処理をおこなうカーネル、MHMaskAttentionOutの実装から取りかかります。このカーネルは、従来のバニラTransformer用カーネルを基本にしつつ、新しいマスキングメカニズムに対応できるようにいくつかの変更を加えていきます。
これまでの実装と同様に、このカーネルは事前に計算されたQuery、Key、Valueの各エンティティを格納したグローバルバッファへのポインタを受け取ります。さらに、アテンション係数用バッファと出力結果用バッファへのポインタも含めます。そして今回は、新たにマスキング用のグローバルバッファおよびマスクしきい値パラメータへのポインタを追加で導入します。
__kernel void MHMaskAttentionOut(__global const float *q, ///<[in] Matrix of Querys __global const float *kv, ///<[in] Matrix of Keys __global float *score, ///<[out] Matrix of Scores __global const float *mask, ///<[in] Mask Matrix __global float *out, ///<[out] Matrix of attention const int dimension, ///< Dimension of Key const int heads_kv, const float mask_level ) { //--- init const int q_id = get_global_id(0); const int k = get_global_id(1); const int h = get_global_id(2); const int qunits = get_global_size(0); const int kunits = get_global_size(1); const int heads = get_global_size(2);
これまでと同様に、カーネルは三次元のタスク空間(Query、Key、Heads)で起動する予定です。同一のQuery内でアテンションヘッド間のスレッドがデータを共有できるように、ローカルワークグループを作成します。カーネル本体では、まず現在のタスク空間における処理の流れを特定し、タスク空間の各パラメータを定義します。
次に、データバッファ内のオフセットを計算し、取得した値をローカル変数に保存します。
const int h_kv = h % heads_kv; const int shift_q = dimension * (q_id * heads + h); const int shift_k = dimension * (2 * heads_kv * k + h_kv); const int shift_v = dimension * (2 * heads_kv * k + heads_kv + h_kv); const int shift_s = kunits * (q_id * heads + h) + k;
続いて、現在のスレッドに対応するアテンションマスクを評価し、その他の補助定数を準備します。
const bool b_mask = (mask[shift_s] < mask_level); const uint ls = min((uint)get_local_size(1), (uint)LOCAL_ARRAY_SIZE); float koef = sqrt((float)dimension); if(koef < 1) koef = 1;
次に、ワークグループ内のスレッド間でデータを交換するために、ローカルメモリ上に配列を作成します。
__local float temp[LOCAL_ARRAY_SIZE];
次に、単一のQuery内の依存係数の指数値の合計を計算します。これを実行するには、個々の合計を繰り返し計算し、それをローカルデータ配列に書き込むループを作成します。
//--- sum of exp uint count = 0; if(k < ls) { temp[k] = 0; do { if(b_mask || q_id >= (count * ls + k)) if((count * ls) < (kunits - k)) { float sum = 0; int sh_k = 2 * dimension * heads_kv * count * ls; for(int d = 0; d < dimension; d++) sum = q[shift_q + d] * kv[shift_k + d + sh_k]; sum = exp(sum / koef); if(isnan(sum)) sum = 0; temp[k] = temp[k] + sum; } count++; } while((count * ls + k) < kunits); } barrier(CLK_LOCAL_MEM_FENCE);
次に、ローカルデータ配列のすべての値を合計します。
do { count = (count + 1) / 2; if(k < ls) temp[k] += (k < count && (k + count) < kunits ? temp[k + count] : 0); if(k + count < ls) temp[k + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
ローカルな総和の計算時には、マスクを考慮して値が算出されたことに注意してください。これを踏まえて、今度はマスキングを考慮したアテンション係数の正規化値を計算することができます。
//--- score float sum = temp[0]; float sc = 0; if(b_mask || q_id >= (count * ls + k)) if(sum != 0) { for(int d = 0; d < dimension; d++) sc = q[shift_q + d] * kv[shift_k + d]; sc = exp(sc / koef) / sum; if(isnan(sc)) sc = 0; } score[shift_s] = sc; barrier(CLK_LOCAL_MEM_FENCE);
アテンション係数を計算する際に、マスクされた要素の値をゼロにしました。したがって、クロスアテンションブロックの結果を計算するために、バニラアルゴリズムを使用できるようになります。
for(int d = 0; d < dimension; d++) { uint count = 0; if(k < ls) do { if((count * ls) < (kunits - k)) { float sum = kv[shift_v + d] * (count == 0 ? sc : score[shift_s + count * ls]); if(isnan(sum)) sum = 0; temp[k] = (count > 0 ? temp[k] : 0) + sum; } count++; } while((count * ls + k) < kunits); barrier(CLK_LOCAL_MEM_FENCE); //--- count = min(ls, (uint)kunits); do { count = (count + 1) / 2; if(k < ls) temp[k] += (k < count && (k + count) < kunits ? temp[k + count] : 0); if(k + count < ls) temp[k + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); //--- out[shift_q + d] = temp[0]; } }
バックプロパゲーションカーネルMHMaskAttentionInsideGradientsのアップグレードはそれほど大規模ではありません。このカーネルは点ごとに呼び出すことが可能です。重要な点は、フィードフォワードパス中に依存係数をゼロ化することで、バニラアルゴリズムをそのまま使用して、誤差勾配をQuery、Key、Valueエンティティに分配できるということです。ただし、この方法ではマスクに誤差勾配を伝播させることができません。そのため、著者の手法ではマスク調整用の勾配項をバニラアルゴリズムに追加することで、この問題を解決しています。
__kernel void MHMaskAttentionInsideGradients(__global const float *q, __global float *q_g, __global const float *kv, __global float *kv_g, __global const float *mask, __global float *mask_g, __global const float *scores, __global const float *gradient, const int kunits, const int heads_kv, const float mask_level ) { ........ ........ //--- Mask's gradient for(int k = q_id; k < kunits; k += qunits) { float m = mask[shift_s + k]; if(m < mask_level) mask_g[shift_s + k] = 0; else mask_g[shift_s + k] = 1 - m; } }
関連するマスクエントリは「1」に正規化されることに注意してください。一方で、無関係なマスクに対しては、モデルの出力に影響を与えないため、誤差勾配はゼロに設定されます。
これで、OpenCLカーネルの実装は完了です。新しく実装したカーネルの完全なソースコードについては、添付ファイルをご参照ください。
2.2 SPFormer法クラスの作成
OpenCLプログラムの変更が完了したところで、次はメインプログラムに進みます。ここでは、全結合層CNeuronBaseOCLからコア機能を継承する新しいクラスCNeuronSPFormerを作成します。ただし、SPFormerに必要な調整は規模も大きく特有なものであるため、以前に実装したクロスアテンションブロックからは継承しない方針としました。以下に新しいクラスの構造を示します。
class CNeuronSPFormer : public CNeuronBaseOCL { protected: uint iWindow; uint iUnits; uint iHeads; uint iSPWindow; uint iSPUnits; uint iSPHeads; uint iWindowKey; uint iLayers; uint iLayersSP; //--- CLayer cSuperPoints; CLayer cQuery; CLayer cSPKeyValue; CLayer cMask; CArrayInt cScores; CLayer cMHCrossAttentionOut; CLayer cCrossAttentionOut; CLayer cResidual; CLayer cQKeyValue; CLayer cMHSelfAttentionOut; CLayer cSelfAttentionOut; CLayer cFeedForward; CBufferFloat cTempSP; CBufferFloat cTempQ; CBufferFloat cTempSelfKV; CBufferFloat cTempCrossKV; //--- virtual bool CreateBuffers(void); virtual bool AttentionOut(CNeuronBaseOCL *q, CNeuronBaseOCL *kv, const int scores, CNeuronBaseOCL *out, CNeuronBaseOCL *mask, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension, const float mask_level = 0.5f); virtual bool AttentionInsideGradients(CNeuronBaseOCL *q, CNeuronBaseOCL *kv, const int scores, CNeuronBaseOCL *out, CNeuronBaseOCL *mask, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension, const float mask_level = 0.5f); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSPFormer(void) {}; ~CNeuronSPFormer(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_sp, uint units_sp, uint heads_sp, uint layers, uint layers_to_sp, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSPFormer; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
提示されたクラス構造には多数の変数やネストされたオブジェクトが含まれており、その多くは以前のアテンション関連クラス実装で使用した名前と一致しています。これは偶然ではありません。実装を進める中で、これらすべてのオブジェクトの機能に慣れていくことになります。
なお、すべての内部オブジェクトはstaticとして宣言されており、そのためコンストラクタとデストラクタは空のままにできます。継承メンバーおよび新規に宣言されたメンバーの初期化は、すべてInitメソッド内でのみおこなわれます。ご存知のように、Initメソッドのパラメータには作成されるオブジェクトのアーキテクチャを明示的に定義する重要な定数が含まれています。
bool CNeuronSPFormer::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_sp, uint units_sp, uint heads_sp, uint layers, uint layers_to_sp, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
メソッドの本体では、まず同名の親クラスのメソッドを呼び出し、そこで継承されたオブジェクトや変数の初期化をおこないます。
その後、取得した定数をすぐにクラスの内部変数に保存します。
iWindow = window; iUnits = units_count; iHeads = heads; iSPUnits = units_sp; iSPWindow = window_sp; iSPHeads = heads_sp; iWindowKey = window_key; iLayers = MathMax(layers, 1); iLayersSP = MathMax(layers_to_sp, 1);
次のステップでは、学習可能なクエリのベクトルを生成するために小さなMLPを初期化します。
//--- Init Querys CNeuronBaseOCL *base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(iWindow * iUnits, 0, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *buf = base.getOutput(); if(!buf || !buf.BufferInit(1, 1) || !buf.BufferWrite()) return false; if(!cQuery.Add(base)) return false; base = new CNeuronBaseOCL(); if(!base.Init(0, 1, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!cQuery.Add(base)) return false;
次に、スーパーポイント抽出ブロックを作成します。ここでは、元のシーケンスのサイズに応じてアーキテクチャが適応する4つの連続したニューラル層ブロックを生成します。次の層の入力シーケンスの長さが2の倍数であれば、残差接続を持つ畳み込みブロックを使用し、シーケンスのサイズを2分の1に削減します。
//--- Init SuperPoints for(int r = 0; r < 4; r++) { if(iSPUnits % 2 == 0) { iSPUnits /= 2; CResidualConv *residual = new CResidualConv(); if(!residual) return false; if(!residual.Init(0, r+2, OpenCL, 2*iSPWindow, iSPWindow, iSPUnits, optimization, iBatch)) return false; if(!cSuperPoints.Add(residual)) return false; }
それ以外の場合は、ストライド1でシーケンスの隣接する2つの要素を解析する単純な畳み込み層を使用します。これにより、シーケンスの長さは1つ分だけ短くなります。
else { iSPUnits--; CNeuronConvOCL *conv = new CNeuronConvOCL(); if(!conv.Init(0, r+2, OpenCL, 2*iSPWindow, iSPWindow, iSPWindow, iSPUnits, 1, optimization, iBatch)) return false; if(!cSuperPoints.Add(conv)) return false; } }
データ前処理オブジェクトを初期化しました。次に、変更されたTransformerデコーダの内部層の初期化に進みます。これをおこなうために、オブジェクトへのポインタを一時的に保存するローカル変数を作成し、デコーダの内部層の指定された数に等しい回数のループを構成します。
CNeuronConvOCL *conv = NULL; CNeuronTransposeOCL *transp = NULL; for(uint l = 0; l < iLayers; l++) { //--- Cross Attention //--- Query conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 6, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; if(!cQuery.Add(conv)) return false; //--- Key-Value if(l % iLayersSP == 0) { conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 7, OpenCL, iSPWindow, iSPWindow, iWindowKey * iSPHeads, iSPUnits, 1, optimization, iBatch)) return false; if(!cSPKeyValue.Add(conv)) return false; }
ここではまず、Query、Key、Valueエンティティを生成する内部層を初期化します。Key-Valueテンソルは必要な場合にのみ生成されます。
ここではマスク生成層も追加します。これには、スーパーポイントシーケンスの各要素に対してすべてのクエリのマスキング係数を生成する畳み込み層を使用します。マルチヘッドアテンションアルゴリズムを使用しているため、各アテンションヘッドごとに係数も生成します。値の正規化にはシグモイド活性化関数を用います。
//--- Mask conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 8, OpenCL, iSPWindow, iSPWindow, iUnits * iHeads, iSPUnits, 1, optimization, iBatch)) return false; conv.SetActivationFunction(SIGMOID); if(!cMask.Add(conv)) return false;
ここで注意すべきなのは、クロスアテンションをおこなう際にスーパーポイントクエリのアテンション係数が必要になるため、得られたマスキングテンソルの転置をおこなうという点です。
transp = new CNeuronTransposeOCL(); if(!transp) return false; if(!transp.Init(0, l * 14 + 9, OpenCL, iSPUnits, iUnits * iHeads, optimization, iBatch)) return false; if(!cMask.Add(transp)) return false;
次のステップは、クロスアテンションの結果を記録するためのオブジェクトを準備することです。まず、マルチヘッドアテンションから始めます。
//--- MH Cross Attention out base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, l * 14 + 10, OpenCL, iWindow * iUnits * iHeads, optimization, iBatch)) return false; if(!cMHCrossAttentionOut.Add(base)) return false;
次に、圧縮された表現に対して同じことをおこないます。
//--- Cross Attention out conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 11, OpenCL, iWindow * iHeads, iWindow * iHeads, iWindow, iUnits, 1, optimization, iBatch)) return false; if(!cCrossAttentionOut.Add(conv)) return false;
次に、元のデータとの加算をおこなう層を追加します。
//--- Residual base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, l * 14 + 12, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!cResidual.Add(base)) return false;
これに自己アテンションブロックが続きます。ここでもQuery、Key、Valueエンティティを生成しますが、今回はクロスアテンションの結果を使用します。
//--- Self-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l*14+13, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; if(!cQuery.Add(conv)) return false; //--- Key-Value if(l % iLayersSP == 0) { conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l*14+14, OpenCL, iWindow, iWindow, iWindowKey * iSPHeads, iUnits, 1, optimization, iBatch)) return false; if(!cQKeyValue.Add(conv)) return false; }
次に、マルチヘッドアテンションと圧縮された値の結果を記録するためのオブジェクトを追加します。
//--- MH Attention out base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, l * 14 + 15, OpenCL, iWindow * iUnits * iHeads, optimization, iBatch)) return false; if(!cMHSelfAttentionOut.Add(base)) return false; //--- Attention out conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 16, OpenCL, iWindow * iHeads, iWindow * iHeads, iWindow, iUnits, 1, optimization, iBatch)) return false; if(!cSelfAttentionOut.Add(conv)) return false;
クロスアテンションの結果との加算をおこなう層を追加します。
//--- Residual base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, l * 14 + 17, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!cResidual.Add(base)) return false;
次に、残差接続を持つFeedForwardブロックを追加します。
//--- FeedForward conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 18, OpenCL, iWindow, iWindow, iWindow * 4, iUnits, 1, optimization, iBatch)) return false; conv.SetActivationFunction(LReLU); if(!cFeedForward.Add(conv)) return false; conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 19, OpenCL, iWindow * 4, iWindow * 4, iWindow, iUnits, 1, optimization, iBatch)) return false; if(!cFeedForward.Add(conv)) return false; //--- Residual base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, l * 14 + 20, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!cResidual.Add(base)) return false; if(!base.SetGradient(conv.getGradient())) return false;
不要なデータコピー操作を避けるために、FeedForwardブロックの最終層と残差接続層の誤差勾配バッファを結合していることに注意してください。最終内部層の結果バッファと上位の誤差勾配に対しても同様の操作をおこないます。
if(l == (iLayers - 1)) { if(!SetGradient(conv.getGradient())) return false; if(!SetOutput(base.getOutput())) return false; } }
オブジェクトの初期化プロセスにおいて、アテンション係数データのバッファは作成しなかったことに注意してください。その作成と内部オブジェクトの初期化は、別のメソッドに移動しました。
//--- SetOpenCL(OpenCL); //--- return true; }
内部オブジェクトを初期化した後、フィードフォワードパスメソッドの構築に移ります。上記で作成したカーネルを呼び出すメソッドのアルゴリズムについては、特に新しい点がないため、独自に学習するためにここでは割愛します。ここでは、トップレベルのfeedForwardメソッドのアルゴリズムにのみ注目し、SPFormerアルゴリズムの明確な処理の流れを構築します。
bool CNeuronSPFormer::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL *superpoints = NeuronOCL; CNeuronBaseOCL *neuron = NULL, *inputs = NULL, *q = NULL, *kv_cross = NULL, *kv_self = NULL;
メソッドパラメータでは、ソースデータオブジェクトへのポインタを受け取ります。メソッドの本体では、オブジェクトへのポインタを一時的に保存するためのローカル変数をいくつか宣言します。
次に、結果の生データをスーパーポイント抽出モデルに実行します。
//--- Superpoints for(int l = 0; l < cSuperPoints.Total(); l++) { neuron = cSuperPoints[l]; if(!neuron || !neuron.FeedForward(superpoints)) return false; superpoints = neuron; }
そして、クエリのベクトルを生成します。
//--- Query neuron = cQuery[1]; if(!neuron || !neuron.FeedForward(cQuery[0])) return false;
これで準備作業は完了です。デコーダの内部ニューラル層を反復処理するためのループを作成します。
inputs = neuron; for(uint l = 0; l < iLayers; l++) { //--- Cross Attentionn q = cQuery[l * 2 + 2]; if(!q || !q.FeedForward(inputs)) return false; if((l % iLayersSP) == 0) { kv_cross = cSPKeyValue[l / iLayersSP]; if(!kv_cross || !kv_cross.FeedForward(superpoints)) return false; }
ここではまず、Query、Key、Valueエンティティを準備します。
マスクを生成します。
neuron = cMask[l * 2]; if(!neuron || !neuron.FeedForward(superpoints)) return false; neuron = cMask[l * 2 + 1]; if(!neuron || !neuron.FeedForward(cMask[l * 2])) return false;
次に、マスキングを考慮しながらクロスアテンションアルゴリズムを実行します。
if(!AttentionOut(q, kv_cross, cScores[l * 2], cMHCrossAttentionOut[l], neuron, iUnits, iHeads, iSPUnits, iSPHeads, iWindowKey)) return false;
マルチヘッドアテンションの結果をクエリテンソルのサイズに縮小します。
neuron = cCrossAttentionOut[l]; if(!neuron || !neuron.FeedForward(cMHCrossAttentionOut[l])) return false;
その後、2つの情報ストリームからのデータを合計して正規化します。
q = inputs; inputs = cResidual[l * 3]; if(!inputs || !SumAndNormilize(q.getOutput(), neuron.getOutput(), inputs.getOutput(), iWindow, true, 0, 0, 0, 1)) return false;
クロスアテンションブロックの次には自己アテンションアルゴリズムが続きます。ここで、クロスアテンションの結果に基づいてQuery、Key、Valueエンティティを再度生成します。
//--- Self-Attention q = cQuery[l * 2 + 3]; if(!q || !q.FeedForward(inputs)) return false; if((l % iLayersSP) == 0) { kv_self = cQKeyValue[l / iLayersSP]; if(!kv_self || !kv_self.FeedForward(inputs)) return false; }
この段階ではマスキングは使用しません。したがって、アテンションメソッドを呼び出すときは、マスクオブジェクトの代わりにNULLを指定します。
if(!AttentionOut(q, kv_self, cScores[l * 2 + 1], cMHSelfAttentionOut[l], NULL, iUnits, iHeads, iUnits, iHeads, iWindowKey)) return false;
マルチヘッドアテンションの結果をクエリテンソルのサイズのレベルまで削減します。
neuron = cSelfAttentionOut[l]; if(!neuron || !neuron.FeedForward(cMHSelfAttentionOut[l])) return false;
次に、それをクロスアテンションの結果のベクトルと合計し、データを正規化します。
q = inputs; inputs = cResidual[l * 3 + 1]; if(!inputs || !SumAndNormilize(q.getOutput(), neuron.getOutput(), inputs.getOutput(), iWindow, true, 0, 0, 0, 1)) return false;
次に、通常のTransformerと同様に、FeedForwardブロックを通じてデータを伝播します。その後、内部層を通るループの次の反復に進みます。
//--- FeedForward neuron = cFeedForward[l * 2]; if(!neuron || !neuron.FeedForward(inputs)) return false; neuron = cFeedForward[l * 2 + 1]; if(!neuron || !neuron.FeedForward(cFeedForward[l * 2])) return false; q = inputs; inputs = cResidual[l * 3 + 2]; if(!inputs || !SumAndNormilize(q.getOutput(), neuron.getOutput(), inputs.getOutput(), iWindow, true, 0, 0, 0, 1)) return false; } //--- return true; }
ループの次の反復に進む前に、現在の内部層の最後のオブジェクトへのポインタをinputs変数に保存することに注意してください。
デコーダの内部層ループのすべての反復が正常に完了したら、メソッドの操作のブール結果を呼び出し元プログラムに返します。
次のステップは、バックプロパゲーションパスメソッドを構築することです。特に注目すべきは、モデルの全体出力に対する各要素の寄与に基づいて誤差勾配をすべての要素に分配する役割を持つメソッド、calcInputGradientsです。
bool CNeuronSPFormer::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
メソッドは、フィードフォワードパス中に入力データを提供した前のニューラル層オブジェクトへのポインタを受け取ります。ここでの目的は、その層の入力がモデルの出力に与えた影響度に応じて、誤差勾配をその層へ逆伝播させることです。
メソッドの本体では、まず受け取ったポインタが有効かどうかを検証します。無効な参照のまま続行すると、その後のすべての操作が無意味になるためです。
その後、勾配計算に使用するオブジェクトへのポインタを一時的に格納するためのローカル変数群を宣言します。
CNeuronBaseOCL *superpoints = cSuperPoints[cSuperPoints.Total() - 1]; CNeuronBaseOCL *neuron = NULL, *inputs = NULL, *q = NULL, *kv_cross = cSPKeyValue[cSPKeyValue.Total() - 1], *kv_self = cQKeyValue[cQKeyValue.Total() - 1];
中間データを一時的に保存するためのバッファをリセットします。
if(!cTempSP.Fill(0) || !cTempSelfKV.Fill(0) || !cTempCrossKV.Fill(0)) return false;
次に、デコーダの内部層を通る逆ループを構成します。
for(int l = int(iLayers - 1); l >= 0; l--) { //--- FeedForward neuron = cFeedForward[l * 2]; if(!neuron || !neuron.calcHiddenGradients(cFeedForward[l * 2 + 1])) return false;
ご存じのように、クラスオブジェクトの初期化時に、上位レベルの誤差勾配バッファと残差接続層へのポインタを、FeedForwardブロックの最終層のものに置き換えました。この設計により、バックプロパゲーションはFeedForwardブロックから直接開始できるため、上位バッファや残差接続層からFeedForwardの最終層へ誤差勾配を手動で渡す必要がなくなります。
これに続いて、誤差勾配を自己アテンションブロックの残差接続層まで伝播します。
neuron = cResidual[l * 3 + 1]; if(!neuron || !neuron.calcHiddenGradients(cFeedForward[l * 2])) return false;
その後、2つのデータストリームからの誤差勾配を合計し、それを自己アテンション結果層に渡します。
if(!SumAndNormilize(((CNeuronBaseOCL*)cResidual[l * 3 + 2]).getGradient(), neuron.getGradient(), ((CNeuronBaseOCL*)cSelfAttentionOut[l]).getGradient(), iWindow, false, 0, 0, 0, 1)) return false;
次に、得られた誤差勾配をアテンションヘッド間で分配します。
//--- Self-Attention neuron = cMHSelfAttentionOut[l]; if(!neuron || !neuron.calcHiddenGradients(cSelfAttentionOut[l])) return false;
自己アテンションブロックのQuery、Key、Valueエンティティバッファへのポインタを取得します。必要に応じて、中間値を蓄積するためのバッファをリセットします。
q = cQuery[l * 2 + 3]; if(((l + 1) % iLayersSP) == 0) { kv_self = cQKeyValue[l / iLayersSP]; if(!kv_self || !cTempSelfKV.Fill(0)) return false; }
次に、モデルのパフォーマンス結果の影響に応じて、誤差勾配をそれらに転送します。
if(!AttentionInsideGradients(q, kv_self, cScores[l * 2 + 1], neuron, NULL, iUnits, iHeads, iUnits, iHeads, iWindowKey)) return false;
デコーダの複数の内部層に1つのKey-Valueテンソルを使用する可能性を提供しました。したがって、現在の内部層のインデックスに応じて、取得した値と以前に蓄積された誤差勾配を合計し、対応するKey-Value層の一時データ蓄積バッファまたは勾配バッファに格納します。
if(iLayersSP > 1) { if((l % iLayersSP) == 0) { if(!SumAndNormilize(kv_self.getGradient(), GetPointer(cTempSelfKV), kv_self.getGradient(), iWindowKey, false, 0, 0, 0, 1)) return false; } else { if(!SumAndNormilize(kv_self.getGradient(), GetPointer(cTempSelfKV), GetPointer(cTempSelfKV), iWindowKey, false, 0, 0, 0, 1)) return false; } }
次に、誤差勾配をクロスアテンションブロックの残差接続層まで伝播します。ここではまず、Queryエンティティからの誤差勾配を渡します。
inputs = cResidual[l * 3]; if(!inputs || !inputs.calcHiddenGradients(q, NULL)) return false;
そして、必要に応じて、Key-Value情報フローからの誤差勾配を追加します。
if((l % iLayersSP) == 0) { CBufferFloat *temp = inputs.getGradient(); if(!inputs.SetGradient(GetPointer(cTempQ), false)) return false; if(!inputs.calcHiddenGradients(kv_self, NULL)) return false; if(!SumAndNormilize(temp, GetPointer(cTempQ), temp, iWindow, false, 0, 0, 0, 1)) return false; if(!inputs.SetGradient(temp, false)) return false; }
次に、自己アテンションブロックの残差フローからの誤差勾配を追加し、受信した値をクロスアテンションブロックに渡します。
if(!SumAndNormilize(((CNeuronBaseOCL*)cSelfAttentionOut[l]).getGradient(), inputs.getGradient(), ((CNeuronBaseOCL*)cCrossAttentionOut[l]).getGradient(), iWindow, false, 0, 0, 0, 1)) return false;
その後、クロスアテンションブロックを通じて誤差勾配を伝播する必要があります。まず、誤差勾配をアテンションヘッド全体に分散します。
//--- Cross Attention neuron = cMHCrossAttentionOut[l]; if(!neuron || !neuron.calcHiddenGradients(cCrossAttentionOut[l])) return false;
自己アテンションと同様に、Query、Key、Valueエンティティオブジェクトへのポインタを取得します。
q = cQuery[l * 2 + 2]; if(((l + 1) % iLayersSP) == 0) { kv_cross = cSPKeyValue[l / iLayersSP]; if(!kv_cross || !cTempCrossKV.Fill(0)) return false; }
次に、誤差勾配をアテンションブロックを通じて伝播します。ただし、この場合は、マスキングオブジェクトへのポインタを追加します。
if(!AttentionInsideGradients(q, kv_cross, cScores[l * 2], neuron, cMask[l * 2 + 1], iUnits, iHeads, iSPUnits, iSPHeads, iWindowKey)) return false;
Queryエンティティからの誤差勾配は、前のデコーダ層またはクエリベクトルに渡されます。オブジェクトの選択は、現在のデコーダ層によって異なります。
inputs = (l == 0 ? cQuery[1] : cResidual[l * 3 - 1]); if(!inputs.calcHiddenGradients(q, NULL)) return false;
ここで、残差接続情報フローに沿って誤差勾配を追加します。
if(!SumAndNormilize(inputs.getGradient(), ((CNeuronBaseOCL*)cCrossAttentionOut[l]).getGradient(), inputs.getGradient(), iWindow, false, 0, 0, 0, 1)) return false;
この段階で、クエリベクトル経路に沿った勾配伝播が完了しました。ただし、誤差勾配をスーパーポイント経路を通じて逆伝播する必要があります。これをおこなうには、まず、Key-Valueテンソルから勾配を伝播する必要があるかどうかを確認します。そうであれば、計算された勾配は、以前に累積された誤差勾配を含むバッファに累積されます。
if((l % iLayersSP) == 0) { if(!superpoints.calcHiddenGradients(kv_cross, NULL)) return false; if(!SumAndNormilize(superpoints.getGradient(), GetPointer(cTempSP), GetPointer(cTempSP), iSPWindow, false, 0, 0, 0, 1)) return false; }
次に、マスク生成モデルからの誤差勾配を配布します。
neuron = cMask[l * 2]; if(!neuron || !neuron.calcHiddenGradients(cMask[l * 2 + 1]) || !DeActivation(neuron.getOutput(), neuron.getGradient(), neuron.getGradient(), neuron.Activation())) return false; if(!superpoints.calcHiddenGradients(neuron, NULL)) return false;
得られた値を、以前に累積された誤差勾配に追加します。現在のデコーダ層に注意してください。
if(l == 0) { if(!SumAndNormilize(superpoints.getGradient(), GetPointer(cTempSP), superpoints.getGradient(), iSPWindow, false, 0, 0, 0, 1)) return false; } else if(!SumAndNormilize(superpoints.getGradient(), GetPointer(cTempSP), GetPointer(cTempSP), iSPWindow, false, 0, 0, 0, 1)) return false; }
最初のデコーダ層(実装ではループの最後の反復に相当)を分析する場合、合計勾配はスーパーポイントモデルの最終層のバッファに格納されます。それ以外の場合は、中間保存用の一時バッファに誤差勾配を蓄積します。
次に、デコーダの内部層上の逆ループの次の反復に進みます。
誤差勾配がTransformerデコーダのすべての内部層に正常に伝播されると、最後のステップは、スーパーポイントモデルの層全体に勾配を分散することです。スーパーポイントモデルは線形構造になっているため、その層に対して逆反復ループを簡単に構成できます。
for(int l = cSuperPoints.Total() - 2; l >= 0; l--) { superpoints = cSuperPoints[l]; if(!superpoints || !superpoints.calcHiddenGradients(cSuperPoints[l + 1])) return false; }
メソッド操作の最後に、スーパーポイントモデルからソースデータ層に誤差勾配を渡し、メソッド操作の実行の論理結果を呼び出し元プログラムに返します。
if(!NeuronOCL.calcHiddenGradients(superpoints, NULL)) return false; //--- return true; }
この段階で、モデルの全体的な性能への影響に応じて、内部のすべてのコンポーネントおよび入力データに対して誤差勾配を伝播させる処理を実装しました。次におこなうのは、合計誤差を最小化するためにモデルの訓練可能なパラメータを最適化することです。これらの操作はupdateInputWeightsメソッド内でおこなわれます。
重要なのは、モデルのすべての訓練可能なパラメータがクラス内の内部オブジェクトに格納されており、これらのパラメータの最適化アルゴリズムは既にそれらのオブジェクト内で実装されているという点です。したがって、パラメータ更新メソッドでは、ネストされたオブジェクトの対応するメソッドを順に呼び出すだけで十分です。このメソッドの実装については、ご自身で確認されることをお勧めします。なお、新しいクラスおよびそのすべてのコンポーネントの完全なソースコードは添付資料に含まれています。
訓練可能モデルのアーキテクチャは、訓練および環境との相互作用を支えるすべてのプログラムとともに以前の作業から完全に継承されています。エンコーダのアーキテクチャには若干の調整のみが施されているので、こちらもぜひ独自に検証してみてください。この記事の開発に使用されたすべてのクラスやユーティリティの完全なコードは添付ファイルに含まれています。次に、作業の最終段階であるモデルの訓練とテストに進みます。
3.テスト
この記事では、SPFormer法で提案されたアプローチの解釈を実装するための膨大な作業を完了しました。次に、モデルの訓練およびテストのフェーズに移り、実際の履歴データを用いてActor方策の評価を行います。
モデルの訓練には、2023年のEURUSD銘柄のH1時間枠における実際の履歴データを使用しました。すべてのインジケーターのパラメータはデフォルト値のままとしています。
訓練アルゴリズムおよび訓練・評価のための支援プログラムは、これまでの出版物から継承しています。
訓練済みのActor方策は、2024年1月の実際の履歴データを用いてMetaTrader 5のストラテジーテスターでテストされ、他のすべてのパラメータは変更していません。以下にそのテスト結果を示します。
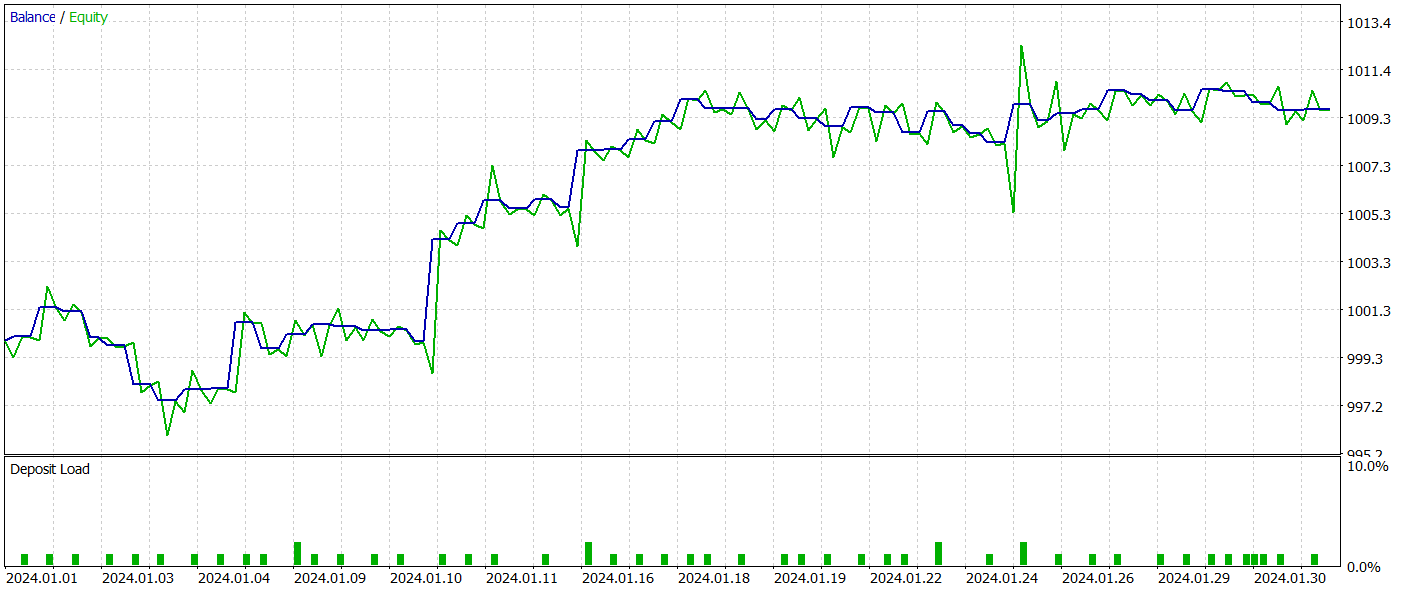
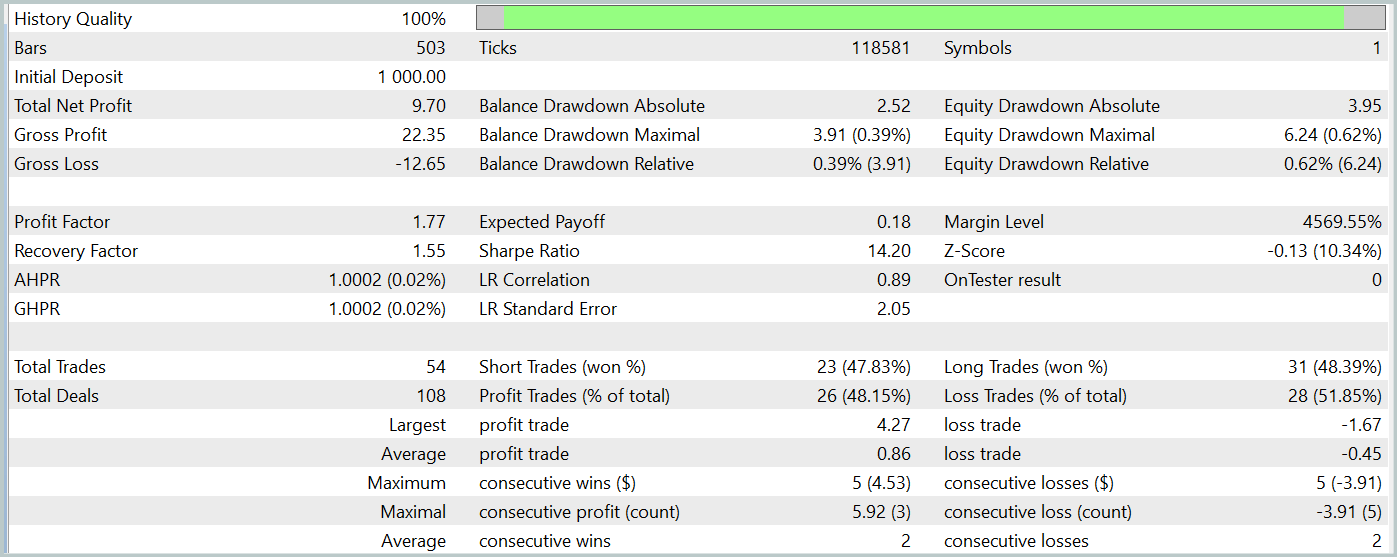
テスト期間中、モデルは54回の取引をおこない、そのうち26回が利益確定となりました。これは全取引の48%に相当します。利益を出した取引の平均利益は、損失取引の同様の指標の2倍でした。このため、テスト期間中にモデルは利益を上げることができました。
しかしながら、テスト期間中の取引回数が限られているため、モデルの長期的な信頼性やパフォーマンスを評価するには十分な根拠とは言えない点に注意が必要です。
結論
SPFormer法は、市場データのセグメンテーションや市場シグナルの予測において、取引アプリケーションへの適用可能性を示しています。従来のモデルが中間ステップに依存し、ノイズに敏感になりやすいのに対し、本手法は市場情報のスーパーポイント表現に直接作用します。Transformerアーキテクチャを用いることで処理の簡素化、予測精度の向上、そして取引における意思決定の迅速化が期待できます。
本記事の実践部分では、MQL5を用いて提案手法の実装をおこない、実際の履歴データを用いて訓練・検証を実施しました。テスト結果からは利益を生み出す能力が確認され、実運用への可能性が示唆されました。ただし、ここで示した実装はあくまでデモンストレーション目的のものであり、実際の取引環境への適用にあたっては、長期間にわたる追加訓練および徹底した検証・テストを通じて堅牢性と信頼性を十分に確保する必要があります。
参考文献記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 事例収集のためのEA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | Test.mq5 | EA | モデルテストEA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | ライブラリ | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/15928
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索